Developer Hadoop 2.0 Certification exam for Pig and Hive Developer v7.0
Question 1
You want to perform analysis on a large collection of images. You want to store this data in
HDFS and process it with MapReduce but you also want to give your data analysts and data scientists the ability to process the data directly from HDFS with an interpreted high- level programming language like Python. Which format should you use to store this data in
HDFS?
- A. SequenceFiles
- B. Avro
- C. JSON
- D. HTML
- E. XML
- F. CSV
Answer : B
Reference: Hadoop binary files processing introduced by image duplicates finder
Question 2
Consider the following two relations, A and B.

What is the output of the following Pig commands?
X = GROUP A BY S1;
DUMP X;

- A. Option A
- B. Option B
- C. Option C
- D. Option D
Answer : D
Question 3
Which one of the following statements is true regarding a MapReduce job?
- A. The job's Partitioner shuffles and sorts all (key.value) pairs and sends the output to all reducers
- B. The default Hash Partitioner sends key value pairs with the same key to the same Reducer
- C. The reduce method is invoked once for each unique value
- D. The Mapper must sort its output of (key.value) pairs in descending order based on value
Answer : A
Question 4
What is a SequenceFile?
- A. A SequenceFile contains a binary encoding of an arbitrary number of homogeneous writable objects.
- B. A SequenceFile contains a binary encoding of an arbitrary number of heterogeneous writable objects.
- C. A SequenceFile contains a binary encoding of an arbitrary number of WritableComparable objects, in sorted order.
- D. A SequenceFile contains a binary encoding of an arbitrary number key-value pairs. Each key must be the same type. Each value must be same type.
Answer : D
Explanation: SequenceFile is a flat file consisting of binary key/value pairs.
There are 3 different SequenceFile formats:
Uncompressed key/value records.
Record compressed key/value records - only 'values' are compressed here.
Block compressed key/value records - both keys and values are collected in 'blocks' separately and compressed. The size of the 'block' is configurable.
Reference: http://wiki.apache.org/hadoop/SequenceFile
Question 5
Which Hadoop component is responsible for managing the distributed file system metadata?
- A. NameNode
- B. Metanode
- C. DataNode
- D. NameSpaceManager
Answer : A
Question 6
Examine the following Pig commands:
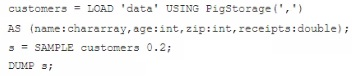
Which one of the following statements is true?
- A. The SAMPLE command generates an "unexpected symbol" error
- B. Each MapReduce task will terminate after executing for 0.2 minutes
- C. The reducers will only output the first 20% of the data passed from the mappers
- D. A random sample of approximately 20% of the data will be output
Answer : D
Question 7
For each input key-value pair, mappers can emit:
- A. As many intermediate key-value pairs as designed. There are no restrictions on the types of those key-value pairs (i.e., they can be heterogeneous).
- B. As many intermediate key-value pairs as designed, but they cannot be of the same type as the input key-value pair.
- C. One intermediate key-value pair, of a different type.
- D. One intermediate key-value pair, but of the same type.
- E. As many intermediate key-value pairs as designed, as long as all the keys have the same types and all the values have the same type.
Answer : E
Explanation: Mapper maps input key/value pairs to a set of intermediate key/value pairs.
Maps are the individual tasks that transform input records into intermediate records. The transformed intermediate records do not need to be of the same type as the input records.
A given input pair may map to zero or many output pairs.
Reference: Hadoop Map-Reduce Tutorial
Question 8
You have just executed a MapReduce job. Where is intermediate data written to after being emitted from the Mappers map method?
- A. Intermediate data in streamed across the network from Mapper to the Reduce and is never written to disk.
- B. Into in-memory buffers on the TaskTracker node running the Mapper that spill over and are written into HDFS.
- C. Into in-memory buffers that spill over to the local file system of the TaskTracker node running the Mapper.
- D. Into in-memory buffers that spill over to the local file system (outside HDFS) of the TaskTracker node running the Reducer
- E. Into in-memory buffers on the TaskTracker node running the Reducer that spill over and are written into HDFS.
Answer : C
Explanation: The mapper output (intermediate data) is stored on the Local file system
(NOT HDFS) of each individual mapper nodes. This is typically a temporary directory location which can be setup in config by the hadoop administrator. The intermediate data is cleaned up after the Hadoop Job completes.
Reference: 24 Interview Questions & Answers for Hadoop MapReduce developers, Where is the Mapper Output (intermediate kay-value data) stored ?
Question 9
Analyze each scenario below and indentify which best describes the behavior of the default partitioner?
- A. The default partitioner assigns key-values pairs to reduces based on an internal random number generator.
- B. The default partitioner implements a round-robin strategy, shuffling the key-value pairs to each reducer in turn. This ensures an event partition of the key space.
- C. The default partitioner computes the hash of the key. Hash values between specific ranges are associated with different buckets, and each bucket is assigned to a specific reducer.
- D. The default partitioner computes the hash of the key and divides that valule modulo the number of reducers. The result determines the reducer assigned to process the key-value pair.
- E. The default partitioner computes the hash of the value and takes the mod of that value with the number of reducers. The result determines the reducer assigned to process the key-value pair.
Answer : D
Explanation: The default partitioner computes a hash value for the key and assigns the partition based on this result.
The default Partitioner implementation is called HashPartitioner. It uses the hashCode() method of the key objects modulo the number of partitions total to determine which partition to send a given (key, value) pair to.
In Hadoop, the default partitioner is HashPartitioner, which hashes a records key to determine which partition (and thus which reducer) the record belongs in.The number of partition is then equal to the number of reduce tasks for the job.
Reference: Getting Started With (Customized) Partitioning
Question 10
You have user profile records in your OLPT database, that you want to join with web logs you have already ingested into the Hadoop file system. How will you obtain these user records?
- A. HDFS command
- B. Pig LOAD command
- C. Sqoop import
- D. Hive LOAD DATA command
- E. Ingest with Flume agents
- F. Ingest with Hadoop Streaming
Answer : C
Reference: Hadoop and Pig for Large-Scale Web Log Analysis
Question 11
Which TWO of the following statements are true regarding Hive? Choose 2 answers
- A. Useful for data analysts familiar with SQL who need to do ad-hoc queries
- B. Offers real-time queries and row level updates
- C. Allows you to define a structure for your unstructured Big Data
- D. Is a relational database
Answer : AC
Question 12
Which one of the following is NOT a valid Oozie action?
- A. mapreduce
- B. pig
- C. hive
- D. mrunit
Answer : D
Question 13
The Hadoop framework provides a mechanism for coping with machine issues such as faulty configuration or impending hardware failure. MapReduce detects that one or a number of machines are performing poorly and starts more copies of a map or reduce task.
All the tasks run simultaneously and the task finish first are used. This is called:
- A. Combine
- B. IdentityMapper
- C. IdentityReducer
- D. Default Partitioner
- E. Speculative Execution
Answer : E
Explanation: Speculative execution: One problem with the Hadoop system is that by dividing the tasks across many nodes, it is possible for a few slow nodes to rate-limit the rest of the program. For example if one node has a slow disk controller, then it may be reading its input at only 10% the speed of all the other nodes. So when 99 map tasks are already complete, the system is still waiting for the final map task to check in, which takes much longer than all the other nodes.
By forcing tasks to run in isolation from one another, individual tasks do not know where their inputs come from. Tasks trust the Hadoop platform to just deliver the appropriate input. Therefore, the same input can be processed multiple times in parallel, to exploit differences in machine capabilities. As most of the tasks in a job are coming to a close, the
Hadoop platform will schedule redundant copies of the remaining tasks across several nodes which do not have other work to perform. This process is known as speculative execution. When tasks complete, they announce this fact to the JobTracker. Whichever copy of a task finishes first becomes the definitive copy. If other copies were executing speculatively, Hadoop tells the TaskTrackers to abandon the tasks and discard their outputs. The Reducers then receive their inputs from whichever Mapper completed successfully, first.
Reference: Apache Hadoop, Module 4: MapReduce
Note:
* Hadoop uses "speculative execution." The same task may be started on multiple boxes.
The first one to finish wins, and the other copies are killed.
Failed tasks are tasks that error out.
* There are a few reasons Hadoop can kill tasks by his own decisions: a) Task does not report progress during timeout (default is 10 minutes) b) FairScheduler or CapacityScheduler needs the slot for some other pool (FairScheduler) or queue (CapacityScheduler). c) Speculative execution causes results of task not to be needed since it has completed on other place.
Reference: Difference failed tasks vs killed tasks
Question 14
In a MapReduce job, the reducer receives all values associated with same key. Which statement best describes the ordering of these values?
- A. The values are in sorted order.
- B. The values are arbitrarily ordered, and the ordering may vary from run to run of the same MapReduce job.
- C. The values are arbitrary ordered, but multiple runs of the same MapReduce job will always have the same ordering.
- D. Since the values come from mapper outputs, the reducers will receive contiguous sections of sorted values.
Answer : B
Explanation:
Note:
* Input to the Reducer is the sorted output of the mappers.
* The framework calls the application's Reduce function once for each unique key in the sorted order.
* Example:
For the given sample input the first map emits:
< Hello, 1>
< World, 1>
< Bye, 1>
< World, 1>
The second map emits:
< Hello, 1>
< Hadoop, 1>
< Goodbye, 1>
< Hadoop, 1>
Question 15
How are keys and values presented and passed to the reducers during a standard sort and shuffle phase of MapReduce?
- A. Keys are presented to reducer in sorted order; values for a given key are not sorted.
- B. Keys are presented to reducer in sorted order; values for a given key are sorted in ascending order.
- C. Keys are presented to a reducer in random order; values for a given key are not sorted.
- D. Keys are presented to a reducer in random order; values for a given key are sorted in ascending order.
Answer : A
Explanation: Reducer has 3 primary phases:
1. Shuffle
The Reducer copies the sorted output from each Mapper using HTTP across the network.
2. Sort
The framework merge sorts Reducer inputs by keys (since different Mappers may have output the same key).
The shuffle and sort phases occur simultaneously i.e. while outputs are being fetched they are merged.
SecondarySort -
To achieve a secondary sort on the values returned by the value iterator, the application should extend the key with the secondary key and define a grouping comparator. The keys will be sorted using the entire key, but will be grouped using the grouping comparator to decide which keys and values are sent in the same call to reduce.
3. Reduce
In this phase the reduce(Object, Iterable, Context) method is called for each <key,
(collection of values)> in the sorted inputs.
The output of the reduce task is typically written to a RecordWriter via
TaskInputOutputContext.write(Object, Object).
The output of the Reducer is not re-sorted.
Reference: org.apache.hadoop.mapreduce, Class
Reducer<KEYIN,VALUEIN,KEYOUT,VALUEOUT>