Hortonworks Data Platform Certified Developer v5.0
Question 1
You want to run Hadoop jobs on your development workstation for testing before you submit them to your production cluster. Which mode of operation in Hadoop allows you to most closely simulate a production cluster while using a single machine?
- A. Run all the nodes in your production cluster as virtual machines on your development workstation.
- B. Run the hadoop command with the –jt local and the –fs file:///options.
- C. Run the DataNode, TaskTracker, NameNode and JobTracker daemons on a single machine.
- D. Run simldooop, the Apache open-source software for simulating Hadoop clusters.
Answer : C
Question 2
You need to run the same job many times with minor variations. Rather than hardcoding all job configuration options in your drive code, youve decided to have your Driver subclass org.apache.hadoop.conf.Configured and implement the org.apache.hadoop.util.Tool interface.
Indentify which invocation correctly passes.mapred.job.name with a value of Example to
Hadoop?
- A. hadoop “mapred.job.name=Example” MyDriver input output
- B. hadoop MyDriver mapred.job.name=Example input output
- C. hadoop MyDrive –D mapred.job.name=Example input output
- D. hadoop setproperty mapred.job.name=Example MyDriver input output
- E. hadoop setproperty (“mapred.job.name=Example”) MyDriver input output
Answer : C
Explanation: Configure the property using the -D key=value notation:
-D mapred.job.name='My Job'
You can list a whole bunch of options by calling the streaming jar with just the -info argument
Reference: Python hadoop streaming : Setting a job name
Question 3
You have user profile records in your OLPT database, that you want to join with web logs you have already ingested into the Hadoop file system. How will you obtain these user records?
- A. HDFS command
- B. Pig LOAD command
- C. Sqoop import
- D. Hive LOAD DATA command
- E. Ingest with Flume agents
- F. Ingest with Hadoop Streaming
Answer : C
Reference: Hadoop and Pig for Large-Scale Web Log Analysis
Question 4
Your client application submits a MapReduce job to your Hadoop cluster. Identify the
Hadoop daemon on which the Hadoop framework will look for an available slot schedule a
MapReduce operation.
- A. TaskTracker
- B. NameNode
- C. DataNode
- D. JobTracker
- E. Secondary NameNode
Answer : D
Explanation: JobTracker is the daemon service for submitting and tracking MapReduce jobs in Hadoop. There is only One Job Tracker process run on any hadoop cluster. Job
Tracker runs on its own JVM process. In a typical production cluster its run on a separate machine. Each slave node is configured with job tracker node location. The JobTracker is single point of failure for the Hadoop MapReduce service. If it goes down, all running jobs are halted. JobTracker in Hadoop performs following actions(from Hadoop Wiki:)
Client applications submit jobs to the Job tracker.
The JobTracker talks to the NameNode to determine the location of the data
The JobTracker locates TaskTracker nodes with available slots at or near the data
The JobTracker submits the work to the chosen TaskTracker nodes.
The TaskTracker nodes are monitored. If they do not submit heartbeat signals often enough, they are deemed to have failed and the work is scheduled on a different
TaskTracker.
A TaskTracker will notify the JobTracker when a task fails. The JobTracker decides what to do then: it may resubmit the job elsewhere, it may mark that specific record as something to avoid, and it may may even blacklist the TaskTracker as unreliable.
When the work is completed, the JobTracker updates its status.
Client applications can poll the JobTracker for information.
Reference: 24 Interview Questions & Answers for Hadoop MapReduce developers, What is a JobTracker in Hadoop? How many instances of JobTracker run on a Hadoop Cluster?
Question 5
Which one of the following statements describes the relationship between the
ResourceManager and the ApplicationMaster?
- A. The ApplicationMaster requests resources from the ResourceManager
- B. The ApplicationMaster starts a single instance of the ResourceManager
- C. The ResourceManager monitors and restarts any failed Containers of the ApplicationMaster
- D. The ApplicationMaster starts an instance of the ResourceManager within each Container
Answer : A
Question 6
You want to perform analysis on a large collection of images. You want to store this data in
HDFS and process it with MapReduce but you also want to give your data analysts and data scientists the ability to process the data directly from HDFS with an interpreted high- level programming language like Python. Which format should you use to store this data in
HDFS?
- A. SequenceFiles
- B. Avro
- C. JSON
- D. HTML
- E. XML
- F. CSV
Answer : B
Reference: Hadoop binary files processing introduced by image duplicates finder
Question 7
Review the following 'data' file and Pig code.
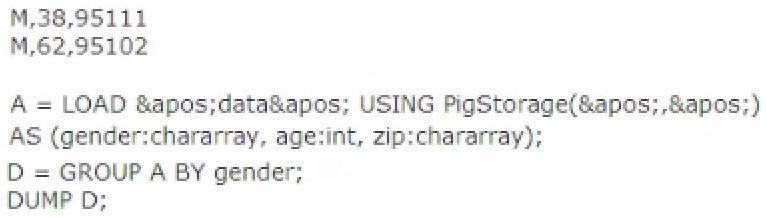
Which one of the following statements is true?
- A. The Output Of the DUMP D command IS (M,{(M,62.95102),(M,38,95111)})
- B. The output of the dump d command is (M, {(38,95in),(62,95i02)})
- C. The code executes successfully but there is not output because the D relation is empty
- D. The code does not execute successfully because D is not a valid relation
Answer : A
Question 8
In Hadoop 2.2, which one of the following statements is true about a standby NameNode?
The Standby NameNode:
- A. Communicates directly with the active NameNode to maintain the state of the active NameNode.
- B. Receives the same block reports as the active NameNode.
- C. Runs on the same machine and shares the memory of the active NameNode.
- D. Processes all client requests and block reports from the appropriate DataNodes.
Answer : B
Question 9
Which best describes what the map method accepts and emits?
- A. It accepts a single key-value pair as input and emits a single key and list of corresponding values as output.
- B. It accepts a single key-value pairs as input and can emit only one key-value pair as output.
- C. It accepts a list key-value pairs as input and can emit only one key-value pair as output.
- D. It accepts a single key-value pairs as input and can emit any number of key-value pair as output, including zero.
Answer : D
Explanation: public class Mapper<KEYIN,VALUEIN,KEYOUT,VALUEOUT> extends Object
Maps input key/value pairs to a set of intermediate key/value pairs.
Maps are the individual tasks which transform input records into a intermediate records.
The transformed intermediate records need not be of the same type as the input records. A given input pair may map to zero or many output pairs.
Reference: org.apache.hadoop.mapreduce
Class Mapper<KEYIN,VALUEIN,KEYOUT,VALUEOUT>
Question 10
Which Hadoop component is responsible for managing the distributed file system metadata?
- A. NameNode
- B. Metanode
- C. DataNode
- D. NameSpaceManager
Answer : A
Question 11
Examine the following Hive statements:
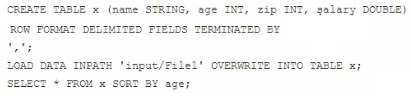
Assuming the statements above execute successfully, which one of the following statements is true?
- A. Each reducer generates a file sorted by age
- B. The SORT BY command causes only one reducer to be used
- C. The output of each reducer is only the age column
- D. The output is guaranteed to be a single file with all the data sorted by age
Answer : A
Question 12
You want to count the number of occurrences for each unique word in the supplied input data. Youve decided to implement this by having your mapper tokenize each word and emit a literal value 1, and then have your reducer increment a counter for each literal 1 it receives. After successful implementing this, it occurs to you that you could optimize this by specifying a combiner. Will you be able to reuse your existing Reduces as your combiner in this case and why or why not?
- A. Yes, because the sum operation is both associative and commutative and the input and output types to the reduce method match.
- B. No, because the sum operation in the reducer is incompatible with the operation of a Combiner.
- C. No, because the Reducer and Combiner are separate interfaces.
- D. No, because the Combiner is incompatible with a mapper which doesnt use the same data type for both the key and value.
- E. Yes, because Java is a polymorphic object-oriented language and thus reducer code can be reused as a combiner.
Answer : A
Explanation: Combiners are used to increase the efficiency of a MapReduce program.
They are used to aggregate intermediate map output locally on individual mapper outputs.
Combiners can help you reduce the amount of data that needs to be transferred across to the reducers. You can use your reducer code as a combiner if the operation performed is commutative and associative. The execution of combiner is not guaranteed, Hadoop may or may not execute a combiner. Also, if required it may execute it more then 1 times.
Therefore your MapReduce jobs should not depend on the combiners execution.
Reference: 24 Interview Questions & Answers for Hadoop MapReduce developers, What are combiners? When should I use a combiner in my MapReduce Job?
Question 13
You are developing a combiner that takes as input Text keys, IntWritable values, and emits
Text keys, IntWritable values. Which interface should your class implement?
- A. Combiner <Text, IntWritable, Text, IntWritable>
- B. Mapper <Text, IntWritable, Text, IntWritable>
- C. Reducer <Text, Text, IntWritable, IntWritable>
- D. Reducer <Text, IntWritable, Text, IntWritable>
- E. Combiner <Text, Text, IntWritable, IntWritable>
Answer : D
Question 14
A NameNode in Hadoop 2.2 manages ______________.
- A. Two namespaces: an active namespace and a backup namespace
- B. A single namespace
- C. An arbitrary number of namespaces
- D. No namespaces
Answer : B
Question 15
In the reducer, the MapReduce API provides you with an iterator over Writable values.
What does calling the next () method return?
- A. It returns a reference to a different Writable object time.
- B. It returns a reference to a Writable object from an object pool.
- C. It returns a reference to the same Writable object each time, but populated with different data.
- D. It returns a reference to a Writable object. The API leaves unspecified whether this is a reused object or a new object.
- E. It returns a reference to the same Writable object if the next value is the same as the previous value, or a new Writable object otherwise.
Answer : C
Explanation: Calling Iterator.next() will always return the SAME EXACT instance of
IntWritable, with the contents of that instance replaced with the next value.
Reference: manupulating iterator in mapreduce