Symmetrix Solutions Expert Exam for Storage Administrators v6.0
Question 1
Storage from an EMC Symmetrix VMAX array has been presented to a number of ESXi servers. The number of LUNs seen by any ESXi server is less than 30 and the LUN numbers are consecutive.
Which VMware parameter can be modified to improve the LUN discovery process during a rescan?
- A. Disk.MaxLUN
- B. Scsi.SCSITimeout_ScanTime
- C. Scsi.MaxReserveTime
- D. Disk.DelayOnBusy
Answer : A
Question 2
You want to configure Concurrent SRDF/Star using Enginuity 5874 and Solutions Enabler
7.x. The workload site will be at Site A, the synchronous target will be at Site B, and the asynchronous target will be at Site C.
Which type of RDF devices will be needed at each site?
- A. R11 at Site A, R21 at Site B, and R22 at Site C
- B. R1 at Site A, R21 at Site B, and R2 at Site C
- C. R11 at Site A, R22 at Site B, and R21 at Site C
- D. R11 at Site A, R22 at Site B, and R22 at Site C
Answer : C
Question 3
A company plans to use Symmetrix VMAX Virtual Provisioning for their VMware ESXi servers. They have standardized on 1 TB VMFS datastores built on single LUNs. However, they want the ability to grow the datastore if required.
What is the recommended Symmetrix VMAX storage allocation and why?
- A. 4 member thin concatenated metavolume (4 x 250 GB). Thin concatenated metavolumes can be easily expanded.
- B. 4 member thin striped metavolume (4 x 250 GB). Thin concatenated metavolumes cannot be expanded.
- C. 8 member thin concatenated metavolume (8 x 125 GB). Thin concatenated metavolumes can be easily expanded.
- D. 8 member thin striped metavolume (8 x 125 GB). Thin concatenated metavolumes cannot be expanded.
Answer : C
Question 4
Some applications running on an EMC Symmetrix VMAX array are experiencing poor performance.
A performance analysis reveals the following:
-> Write response time is impacted
-> Heat Map shows low front-end utilization
-> Heat Map shows high back-end utilization
What is the potential problem?
- A. Logical volume write pending limit has been reached
- B. System-wide write pending limit has been reached
- C. Flexible dynamic cache partitioning has been implemented
- D. Static dynamic cache partitioning has been implemented
Answer : A
Question 5
A storage administrator is configuring Optimizer on an EMC Symmetrix VMAX array. The array is configured entirely with RAID 5 (3+1) devices. All devices are 8 GB and all devices are R1 devices with SRDF/A mirrors on a remote array.
Optimizer has completed the first cycle of performance analysis and has recommended a large number of device swaps to balance the activity on the array. The storage administrator has been asked to minimize the time it takes to complete all the swaps.
What is the minimum configuration of DRV devices that the administrator needs to create?
- A. 8 x RAID 1, 8 GB DRVs
- B. 8 x RAID 5, 8 GB DRVs
- C. 16 x RAID 1, 8 GB DRVs
- D. 16 x RAID 5, 8 GB DRVs
Answer : A
Question 6
A server providing streaming video to clients is configured with storage from an EMC
Symmetrix VMAX array. The data on this server is static and does not change. The file system for the videos is on a 600 GB striped metavolume made up from 8 x 75 GB standard RAID 5 devices.
The storage administrator is baselining the performance of the system using Performance
Manager. The administrator notices that the "seq reads per sec" metric is much lower than expected for a heavy sequential read application.
What is the most likely reason for this situation?
- A. Prefetch algorithm skews the sequential read statistics for heavy sequential workloads
- B. There is not enough cache in the array to handle a heavy sequential read workload
- C. Prefetch is disabled for this metavolume
- D. Metavolume should have been concatenated
Answer : A
Question 7
In an SRDF/Star environment, which event requires an unplanned switch of the production workload?
- A. Network failure between the workload and either target site
- B. Failure of the asynchronous target site
- C. Failure of the synchronous target site
- D. Failure of the workload site
Answer : B
Question 8
A company is planning to migrate their Oracle database to EMC Symmetrix VMAX to support decision support system applications. They would like design guidelines to overcome the existing performance bottlenecks.
What is the key design guideline?
- A. Redo logs and archive logs on separate spindles with RAID 5 protection
- B. Redo logs and archive logs on the same spindles RAID 5 protection
- C. Redo logs and archive logs on the same spindles with RAID 1 protection
- D. Redo logs and archive logs on separate spindles with RAID 1 protection
Answer : D
Question 9
A company plans to install a Symmetrix VMAX in a Fibre Channel SAN environment. They need to protect data access to the Symmetrix port level.
Which feature needs to be implemented?
- A. FCID Lockdown
- B. Hard zoning
- C. RADIUS
- D. CHAP
Answer : A
Question 10
You work in the SAN engineering department for a company that has deployed their
Microsoft Exchange 2010 application on EMC Symmetrix VMAX storage arrays across multiple site locations. The VMAX storage arrays utilize SRDF for disaster recovery. You are required to enforce thin pool utilization limits to avoid any performance implications that could arise from over-subscription.
Which two thin pool parameters should be used?
- A. Maximum subscription and pre-allocate each volume
- B. Write balancing and do not pre-allocate each volume
- C. Rebalancing variance and pre-allocate each volume
- D. Maximum scan device range and do not pre-allocate each volume
Answer : A
Question 11
A company is using Replication Manager to backup their Microsoft Exchange 2010 environment using Microsoft Volume Shadow Service (VSS). Each Exchange database and log volume has separate Symmetrix VMAX LUNs. A Replication Manager backup job for a Microsoft Exchange 2010 server with 20 databases keeps failing to complete a backup.
What could be causing the failure?
- A. Snapshot timeouts are occurring
- B. A virtual mount host is being used for the replicas
- C. Consistency checks are being run in parallel
- D. Insufficient number of gatekeepers have been configured
Answer : A
Question 12
Refer to the Exhibit.
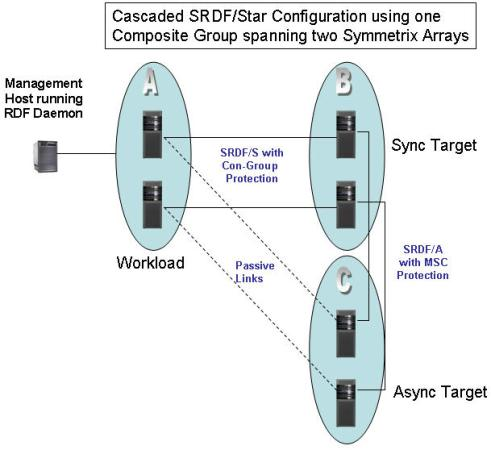
A company has three data centers and has decided to protect its data using SRDF. The replication design must ensure there will be no data loss if Site A fails. All data centers are within 200 km of each other. Either Site B or Site C should be able to take over as production sites in the event of the failure of Site A.
How should SRDF be configured between Sites A and B, and how should devices be configured at Site B?
- A. SRDF/S between Sites A and B with disk-based R21 devices at Site B
- B. SRDF/A between Sites A and B with disk-based R21 devices at Site B
- C. SRDF/S between Sites A and B with disk-less R21 devices at Site B
- D. SRDF/A between Sites A and B with disk-less R21 devices at Site B
Answer : A
Question 13
A company is using Replication Manager to back up multiple Microsoft Exchange 2010 mailbox servers. They have configured a backup job defining the options for performing
VSS backups of each Exchange storage group on each server. All backups are executing successfully, but the company has recently started to experience problems with low disk space on the transaction log volume of one particular storage group.
What is the likely cause for the low disk space?
- A. Online Copy option was specified for that storage group
- B. PreCopy option was specified for that storage group
- C. No Copy option was specified for that storage group
- D. Online Full option was specified for that storage group
Answer : A
Question 14
A company is evaluating SRDF/Star. They are concerned that the RDF daemon represents a single point of failure. How could this concern be addressed?
- A. RDF daemons will be deployed on multiple management stations at the workload site. The RDF daemons will cooperate with each other.
- B. The RDF daemon process runs on the Symmetrix array and has built-in redundancy.
- C. The RDF daemon process runs on the Symmetrix array. If the workload site RDF daemon fails, the RDF daemon from one of the other sites will take over.
- D. RDF daemons will be deployed on one management station at each of the three sites. If the workload site RDF daemon fails, one of the RDF daemons from the other two sites will take over.
Answer : A
Question 15
A company currently has a PowerPath-enabled SAN environment with many hosts. A majority of the hosts have storage allocated from Fibre Channel drives and have poor service time. They intend to design a solution for Symmetrix VMAX storage consolidation to replace their current storage infrastructure.
What is a key design guideline to overcome this issue?
- A. Configure devices to evenly distribute the workload
- B. Implement dynamic cache partitioning
- C. Acquire faster ports
- D. Change PowerPath policy
Answer : A