Designing an Azure Data Solution v1.0
Question 1
You are designing a data processing solution that will implement the lambda architecture pattern. The solution will use Spark running on HDInsight for data processing.
You need to recommend a data storage technology for the solution.
Which two technologies should you recommend? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
- A. Azure Cosmos DB
- B. Azure Service Bus
- C. Azure Storage Queue
- D. Apache Cassandra
- E. Kafka HDInsight
Answer : AE
Explanation:
To implement a lambda architecture on Azure, you can combine the following technologies to accelerate real-time big data analytics:
✑ Azure Cosmos DB, the industry's first globally distributed, multi-model database service.
✑ Apache Spark for Azure HDInsight, a processing framework that runs large-scale data analytics applications
Azure Cosmos DB change feed, which streams new data to the batch layer for HDInsight to process

✑ The Spark to Azure Cosmos DB Connector
E: You can use Apache Spark to stream data into or out of Apache Kafka on HDInsight using DStreams.
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/lambda-architecture
Question 2
A company manufactures automobile parts. The company installs IoT sensors on manufacturing machinery.
You must design a solution that analyzes data from the sensors.
You need to recommend a solution that meets the following requirements:
✑ Data must be analyzed in real-time.
✑ Data queries must be deployed using continuous integration.
✑ Data must be visualized by using charts and graphs.
✑ Data must be available for ETL operations in the future.
✑ The solution must support high-volume data ingestion.
Which three actions should you recommend? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Use Azure Analysis Services to query the data. Output query results to Power BI.
- B. Configure an Azure Event Hub to capture data to Azure Data Lake Storage.
- C. Develop an Azure Stream Analytics application that queries the data and outputs to Power BI. Use Azure Data Factory to deploy the Azure Stream Analytics application.
- D. Develop an application that sends the IoT data to an Azure Event Hub.
- E. Develop an Azure Stream Analytics application that queries the data and outputs to Power BI. Use Azure Pipelines to deploy the Azure Stream Analytics application.
- F. Develop an application that sends the IoT data to an Azure Data Lake Storage container.
Answer : BCD
Question 3
You are designing an Azure Databricks interactive cluster.
You need to ensure that the cluster meets the following requirements:
✑ Enable auto-termination
✑ Retain cluster configuration indefinitely after cluster termination.
What should you recommend?
- A. Start the cluster after it is terminated.
- B. Pin the cluster
- C. Clone the cluster after it is terminated.
- D. Terminate the cluster manually at process completion.
Answer : B
Explanation:
To keep an interactive cluster configuration even after it has been terminated for more than 30 days, an administrator can pin a cluster to the cluster list.
Reference:
https://docs.azuredatabricks.net/user-guide/clusters/terminate.html
Question 4
You are designing a solution for a company. The solution will use model training for objective classification.
You need to design the solution.
What should you recommend?
- A. an Azure Cognitive Services application
- B. a Spark Streaming job
- C. interactive Spark queries
- D. Power BI models
- E. a Spark application that uses Spark MLib.
Answer : E
Explanation:
Spark in SQL Server big data cluster enables AI and machine learning.
You can use Apache Spark MLlib to create a machine learning application to do simple predictive analysis on an open dataset.
MLlib is a core Spark library that provides many utilities useful for machine learning tasks, including utilities that are suitable for:
✑ Classification
✑ Regression
✑ Clustering
✑ Topic modeling
✑ Singular value decomposition (SVD) and principal component analysis (PCA)
✑ Hypothesis testing and calculating sample statistics
Reference:
https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-machine-learning-mllib-ipython
Question 5
A company stores data in multiple types of cloud-based databases.
You need to design a solution to consolidate data into a single relational database. Ingestion of data will occur at set times each day.
What should you recommend?
- A. SQL Server Migration Assistant
- B. SQL Data Sync
- C. Azure Data Factory
- D. Azure Database Migration Service
- E. Data Migration Assistant
Answer : C
Explanation:
Incorrect Answers:
D: Azure Database Migration Service is used to migrate on-premises SQL Server databases to the cloud.
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/introduction https://azure.microsoft.com/en-us/blog/operationalize-azure-databricks-notebooks-using-data-factory/ https://azure.microsoft.com/en-us/blog/data-ingestion-into-azure-at-scale-made-easier-with-latest-enhancements-to-adf-copy-data-tool/
Question 6
HOTSPOT -
You manage an on-premises server named Server1 that has a database named Database1. The company purchases a new application that can access data from
Azure SQL Database.
You recommend a solution to migrate Database1 to an Azure SQL Database instance.
What should you recommend? To answer, select the appropriate configuration in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:

Answer : 
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-import
Question 7
You are designing an application. You plan to use Azure SQL Database to support the application.
The application will extract data from the Azure SQL Database and create text documents. The text documents will be placed into a cloud-based storage solution.
The text storage solution must be accessible from an SMB network share.
You need to recommend a data storage solution for the text documents.
Which Azure data storage type should you recommend?
- A. Queue
- B. Files
- C. Blob
- D. Table
Answer : B
Explanation:
Azure Files enables you to set up highly available network file shares that can be accessed by using the standard Server Message Block (SMB) protocol.
Incorrect Answers:
A: The Azure Queue service is used to store and retrieve messages. It is generally used to store lists of messages to be processed asynchronously.
C: Blob storage is optimized for storing massive amounts of unstructured data, such as text or binary data. Blob storage can be accessed via HTTP or HTTPS but not via SMB.
D: Azure Table storage is used to store large amounts of structured data. Azure tables are ideal for storing structured, non-relational data.
Reference:
https://docs.microsoft.com/en-us/azure/storage/common/storage-introduction https://docs.microsoft.com/en-us/azure/storage/tables/table-storage-overview
Question 8
You are designing an application that will have an Azure virtual machine. The virtual machine will access an Azure SQL database. The database will not be accessible from the Internet.
You need to recommend a solution to provide the required level of access to the database.
What should you include in the recommendation?
- A. Deploy an On-premises data gateway.
- B. Add a virtual network to the Azure SQL server that hosts the database.
- C. Add an application gateway to the virtual network that contains the Azure virtual machine.
- D. Add a virtual network gateway to the virtual network that contains the Azure virtual machine.
Answer : B
Explanation:
When you create an Azure virtual machine (VM), you must create a virtual network (VNet) or use an existing VNet. You also need to decide how your VMs are intended to be accessed on the VNet.
Incorrect Answers:
C: Azure Application Gateway is a web traffic load balancer that enables you to manage traffic to your web applications.
D: A VPN gateway is a specific type of virtual network gateway that is used to send encrypted traffic between an Azure virtual network and an on-premises location over the public Internet.
Reference:
https://docs.microsoft.com/en-us/azure/virtual-machines/network-overview
Question 9
HOTSPOT -
You are designing an application that will store petabytes of medical imaging data
When the data is first created, the data will be accessed frequently during the first week. After one month, the data must be accessible within 30 seconds, but files will be accessed infrequently. After one year, the data will be accessed infrequently but must be accessible within five minutes.
You need to select a storage strategy for the data. The solution must minimize costs.
Which storage tier should you use for each time frame? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer : 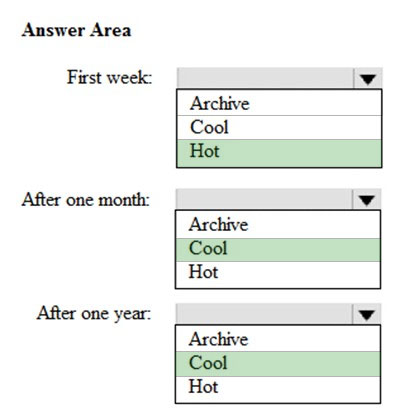
Explanation:
First week: Hot -
Hot - Optimized for storing data that is accessed frequently.
After one month: Cool -
Cool - Optimized for storing data that is infrequently accessed and stored for at least 30 days.
After one year: Cool -
Incorrect Answers:
Archive: Optimized for storing data that is rarely accessed and stored for at least 180 days with flexible latency requirements (on the order of hours).
References:
https://docs.microsoft.com/en-us/azure/storage/blobs/storage-blob-storage-tiers
Question 10
You are designing a data store that will store organizational information for a company. The data will be used to identify the relationships between users. The data will be stored in an Azure Cosmos DB database and will contain several million objects.
You need to recommend which API to use for the database. The API must minimize the complexity to query the user relationships. The solution must support fast traversals.
Which API should you recommend?
- A. MongoDB
- B. Table
- C. Gremlin
- D. Cassandra
Answer : C
Explanation:
Gremlin features fast queries and traversals with the most widely adopted graph query standard.
Reference:
https://docs.microsoft.com/th-th/azure/cosmos-db/graph-introduction?view=azurermps-5.7.0
Question 11
HOTSPOT -
You are designing a new application that uses Azure Cosmos DB. The application will support a variety of data patterns including log records and social media relationships.
You need to recommend which Cosmos DB API to use for each data pattern. The solution must minimize resource utilization.
Which API should you recommend for each data pattern? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:

Answer : 
Explanation:
Log records: SQL -
Social media mentions: Gremlin -
You can store the actual graph of followers using Azure Cosmos DB Gremlin API to create vertexes for each user and edges that maintain the "A-follows-B" relationships. With the Gremlin API, you can get the followers of a certain user and create more complex queries to suggest people in common. If you add to the graph the Content Categories that people like or enjoy, you can start weaving experiences that include smart content discovery, suggesting content that those people you follow like, or finding people that you might have much in common with.
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/social-media-apps
Question 12
You need to recommend a storage solution to store flat files and columnar optimized files. The solution must meet the following requirements:
✑ Store standardized data that data scientists will explore in a curated folder.
✑ Ensure that applications cannot access the curated folder.
✑ Store staged data for import to applications in a raw folder.
✑ Provide data scientists with access to specific folders in the raw folder and all the content the curated folder.
Which storage solution should you recommend?
- A. Azure Synapse Analytics
- B. Azure Blob storage
- C. Azure Data Lake Storage Gen2
- D. Azure SQL Database
Answer : B
Explanation:
Azure Blob Storage containers is a general purpose object store for a wide variety of storage scenarios. Blobs are stored in containers, which are similar to folders.
Incorrect Answers:
C: Azure Data Lake Storage is an optimized storage for big data analytics workloads.
Reference:
https://docs.microsoft.com/en-us/azure/architecture/data-guide/technology-choices/data-storage
Question 13
Your company is an online retailer that can have more than 100 million orders during a 24-hour period, 95 percent of which are placed between 16:30 and 17:00.
All the orders are in US dollars. The current product line contains the following three item categories:
✑ Games with 15,123 items
✑ Books with 35,312 items
✑ Pens with 6,234 items
You are designing an Azure Cosmos DB data solution for a collection named Orders Collection. The following documents is a typical order in Orders Collection.

Orders Collection is expected to have a balanced read/write-intensive workload.
Which partition key provides the most efficient throughput?
- A. Item/Category
- B. OrderTime
- C. Item/Currency
- D. Item/id
Answer : A
Explanation:
Choose a partition key that has a wide range of values and access patterns that are evenly spread across logical partitions. This helps spread the data and the activity in your container across the set of logical partitions, so that resources for data storage and throughput can be distributed across the logical partitions.
Choose a partition key that spreads the workload evenly across all partitions and evenly over time. Your choice of partition key should balance the need for efficient partition queries and transactions against the goal of distributing items across multiple partitions to achieve scalability.
Candidates for partition keys might include properties that appear frequently as a filter in your queries. Queries can be efficiently routed by including the partition key in the filter predicate.
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/partitioning-overview#choose-partitionkey
Question 14
You have a MongoDB database that you plan to migrate to an Azure Cosmos DB account that uses the MongoDB API.
During testing, you discover that the migration takes longer than expected.
You need to recommend a solution that will reduce the amount of time it takes to migrate the data.
What are two possible recommendations to achieve this goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
- A. Increase the Request Units (RUs).
- B. Turn off indexing.
- C. Add a write region.
- D. Create unique indexes.
- E. Create compound indexes.
Answer : AB
Explanation:
A: Increase the throughput during the migration by increasing the Request Units (RUs).
For customers that are migrating many collections within a database, it is strongly recommend to configure database-level throughput. You must make this choice when you create the database. The minimum database-level throughput capacity is 400 RU/sec. Each collection sharing database-level throughput requires at least 100 RU/sec.
B: By default, Azure Cosmos DB indexes all your data fields upon ingestion. You can modify the indexing policy in Azure Cosmos DB at any time. In fact, it is often recommended to turn off indexing when migrating data, and then turn it back on when the data is already in Cosmos DB.
Reference:
https://docs.microsoft.com/bs-latn-ba/Azure/cosmos-db/mongodb-pre-migration
Question 15
You need to recommend a storage solution for a sales system that will receive thousands of small files per minute. The files will be in JSON, text, and CSV formats. The files will be processed and transformed before they are loaded into a data warehouse in Azure Synapse Analytics. The files must be stored and secured in folders.
Which storage solution should you recommend?
- A. Azure Data Lake Storage Gen2
- B. Azure Cosmos DB
- C. Azure SQL Database
- D. Azure Blob storage
Answer : A
Explanation:
Azure provides several solutions for working with CSV and JSON files, depending on your needs. The primary landing place for these files is either Azure Storage or Azure Data Lake Store.1
Azure Data Lake Storage is an optimized storage for big data analytics workloads.
Incorrect Answers:
D: Azure Blob Storage containers is a general purpose object store for a wide variety of storage scenarios. Blobs are stored in containers, which are similar to folders.
Reference:
https://docs.microsoft.com/en-us/azure/architecture/data-guide/scenarios/csv-and-json