Perform Big Data Engineering on Microsoft Cloud Services v1.0
Question 1
You need to use the Cognition.Vision.FaceDetector() function in U-SQL to analyze images.
Which attribute can you detect by using the function?
- A. weight
- B. emotion
- C. hair color
- D. gender
Answer : D
U-SQL provides built-in support for the following cognitive models, allowing you to build applications with powerful algorithms using just a few lines of code:
Face detects one or more human faces in an image, along with face attributes that contain machine learning-based predictions based on features such as age, emotion and gender.
References: https://msdn.microsoft.com/en-us/magazine/mt784661.aspx
Question 2
You have a Microsoft Azure Data Lake Analytics service.
You need to store a list of multiple-character string values in a single column and to use a CROSS APPLY EXPLODE expression to output the values.
Which type of data should you use in a U-SQL query?
- A. byte[]
- B. SQL.ARRAY
- C. string
- D. SQL.MAP
Answer : B
Explanation:
The EXPLODE rowset expression accepts an expression or value of either type SQL.ARRAY, SQL.MAP or IEnumerable and unpacks (explodes) the values into a rowset.
If EXPLODE is applied on an instance of SQL.ARRAY <T>, the resulting rowset contains a single column of type T where each item in the array is placed into its own row. If the array value was empty or null, then the resulting rowset is empty.
Incorrect Answers:
D: If EXPLODE is applied on an instance of SQL.MAP <K,V>, the resulting rowset contains two columns of type K and V respectively where each key-value pair in the map is placed into its own row. If the map value was empty or null, then the resulting rowset is empty.
References: https://msdn.microsoft.com/en-us/azure/data-lake-analytics/u-sql/explode-u-sql
Question 3
You have a Microsoft Azure Data Lake Analytics service.
You plan to configure diagnostic logging.
You need to use Microsoft Operations Management Suite (OMS) to monitor the IP addresses that are used to access the Data Lake Store.
What should you do?
- A. Stream the request logs to an event hub
- B. Stream the audit logs to an event hub
- C. Send the audit logs to Log Analytics
- D. Send the request logs to Log Analytics
Answer : C
Explanation:
A request log captures every API request. An audit log records all operations that are triggered by that API request.
You can analyze the logs with OMS Log Analytics.
References: https://docs.microsoft.com/en-us/azure/security/azure-log-audit
Question 4
HOTSPOT -
You have a Microsoft Azure Data Lake Analytics service.
You have a file named Emloyee.tsv that contains data on employees. Employee.tsv contains seven columns named EmpId, Start, FirstName, LastName, Age,
Department, and Title.
You need to create a Data Lake Analytics job to transform Employee.tsv, define a schema for the data, and output the data to a CSV file. The outputted data must contain only employees who are in the sales department. The Age column must allow NULL.
How should you complete the U-SQL code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:

Answer : 
Explanation:
The following U-SQL script is simple and lets us explore many aspects the U-SQL language.
Copy -
@searchlog =
EXTRACT UserId int,
Start DateTime,
Region string,
Query string,
Duration int?,
Urls string,
ClickedUrls string -
FROM "/Samples/Data/SearchLog.tsv"
USING Extractors.Tsv();
OUTPUT @searchlog -
TO "/output/SearchLog-first-u-sql.csv"
USING Outputters.Csv();
References: https://docs.microsoft.com/en-us/azure/data-lake-analytics/data-lake-analytics-u-sql-get-started
Question 5
You are using Cognitive capabilities in U-SQL to analyze images that contain different types of objects.
You need to identify which objects might be people.
Which two reference assemblies should you use? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. ExtR
- B. ImageTagging
- C. ExtPython
- D. FaceSdk
- E. ImageCommon
Answer : BE
Question 6
DRAG DROP -
You have the following Microsoft Azure services:
-> An Azure Data Lake Store named mydatalake that has a folder named folder1
-> An Azure Storage account named storageacct that has a container named Container1, which contains a folder named folder2
-> An Azure HDInsight cluster named hdcluster, which is configured to access mydatalake and storageacct
You need to copy folder2 to folder1 in hdcluster.
How should you complete the command? To answer, drag the appropriate values to the correct targets. Each value may be used once more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
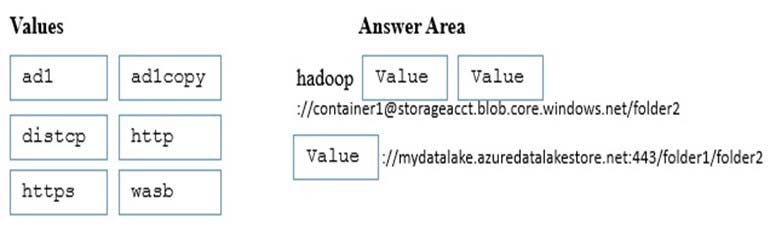
Answer : 
Explanation:
Use Distcp to copy data from Windows Azure Storage Blob (WASB) to a Data Lake Store account.
Example:
hadoop distcp wasb://<container_name>@<storage_account_name>.blob.core.windows.net/example/data/gutenberg adl://
<data_lake_store_account>.azuredatalakestore.net:443/myfolder
References: https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-copy-data-wasb-distcp
Question 7
You plan to create several U-SQL jobs.
You need to store structured data and code that can be shared by the U-SQL jobs.
What should you use?
- A. Microsoft Azure Data Catalog
- B. a U-SQL package
- C. a data-tier application
- D. Microsoft Azure Blob storage
Answer : A
The U-SQL catalog is used to structure data and code so they can be shared by U-SQL scripts. The catalog enables the highest performance possible with data in
Azure Data Lake.
Each Azure Data Lake Analytics account has exactly one U-SQL Catalog associated with it. You cannot delete the U-SQL Catalog. Currently U-SQL Catalogs cannot be shared between Data Lake Store accounts.
Each U-SQL Catalog contains a database called Master. The Master Database cannot be deleted. Each U-SQL Catalog can contain more additional databases.
U-SQL database contain:
-> Assemblies "" share .NET code among U-SQL scripts.
-> Table-values functions "" share U-SQL code among U-SQL scripts.
-> Tables "" share data among U-SQL scripts.
-> Schemas "" share table schemas among U-SQL scripts.
References: https://github.com/Huachao/azure-content/blob/master/articles/data-lake-analytics/data-lake-analytics-use-u-sql-catalog.md
Question 8
You plan to use Microsoft Azure Event Hubs in Azure Stream Analytics to consume time-series aggregations from several published data sources, such as IoT data, reference data, and social media.
You expect TB of data to be consumed daily. All the consumed data will be retained for one week.
You need to recommend a storage solution for the data. The solution must minimize costs.
What should you recommend?
- A. Azure Table Storage
- B. Azure Blob Storage
- C. Azure DocumentDB
- D. Azure Data Lake
Answer : C
Explanation:
Azure Cosmos DB is beneficial in web, mobile, gaming, and IoT applications that need low response times and need to handle massive amounts of reads and writes.
Note: Azure Cosmos DB is Microsoft"™s proprietary globally-distributed, multi-model database service "for managing data at planet-scale" launched in May 2017. It builds upon and extends the earlier Azure DocumentDB, which was released in 2014.
References:
https://azure.microsoft.com/en-us/services/cosmos-db/?v=17.45b https://en.wikipedia.org/wiki/Cosmos_DB
Question 9
You plan to use Microsoft Azure Event Hubs to ingest sensor data. You plan to use Azure Stream Analytics to analyze the data in real time and to send the output directly to Azure Data Lake Store.
You need to write events to the Data Lake Store in batches.
What should you use?
- A. Stream Analytics
- B. the EventHubSender class
- C. the Azure CLI
- D. Apache Storm in Azure HDInsight
Answer : A
Explanation:
Streamed data represents data that can be generated by various sources such as applications, devices, sensors, etc. This data can be ingested into a Data Lake
Store by variety tools. These tools will usually capture and process the data on an event-by-event basis in real-time, and then write the events in batches into Data
Lake Store so that they can be further processed.
References:
https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-data-scenarios
Question 10
DRAG DROP -
You have IoT devices that produce the following output.

You need to use Microsoft Azure Stream Analytics to convert the output into the tabular format described in the following table.

How should you complete the Stream Analytics query? To answer, drag the appropriate values to the correct targets. Each value may be used once more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
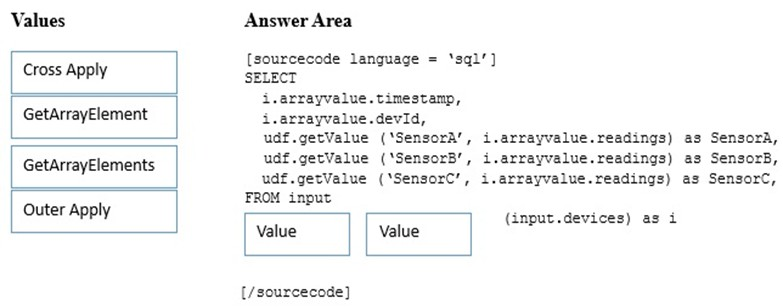
Answer : 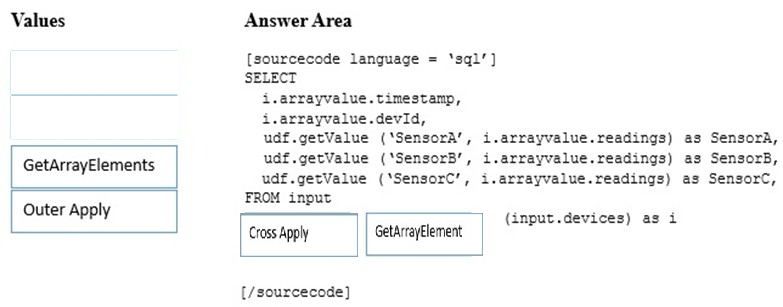
Question 11
You use Microsoft Azure Stream Analytics to analyze website visit logs in real time.
You have a table named Locations that has a column containing IP addresses and a column containing country names.
You need to look up the country name of a specific IP address.
Which query element should you use?
- A. a reference data JOIN
- B. a UNION operator
- C. an input data JOIN
- D. an APPLY operator
Answer : A
Explanation:
Reference data (also known as a lookup table) is a finite data set that is static or slowing changing in nature, used to perform a lookup or to correlate with your data stream. To make use of reference data in your Azure Stream Analytics job, you will generally use a Reference Data Join in your Query.
In a usual scenario, we use an event processing engine to compute streaming data with very low latency. In many cases users need to correlate persisted historical data or a slow changing dataset (aka. reference data) with the real-time event stream to make smarter decisions about the system. For example, join my event stream to a static dataset which maps IP Addresses to locations. This is the only JOIN supported in Stream Analytics where a temporal bound is not necessary.
References:
https://msdn.microsoft.com/en-us/azure/stream-analytics/reference/reference-data-join-azure-stream-analytics
Question 12
You plan to capture the output from a group of 500 IoT devices that produce approximately 10 GB of data per hour by using Microsoft Azure Stream Analytics. The data will be retained for one year.
Once the data is processed, it will be stored in Azure, and then analyzed by using an Azure HDInsight cluster.
You need to select where to store the output data from Stream Analytics. The solution must minimize costs.
What should you select?
- A. Azure SQL Data Warehouse
- B. Azure Table Storage
- C. Azure SQL Database
- D. Azure Blob storage
Answer : D
Explanation:
Example: With an Azure Storage container as a custom endpoint, IoT Hub will write messages to a blob based on the batch frequency and block size specified by the customer. After either the batch size or the batch frequency are hit, whichever happens first, IoT Hub will then write the enqueued messages to the storage container as a blob. You can also specify the naming convention you want to use for your blobs, as shown below.
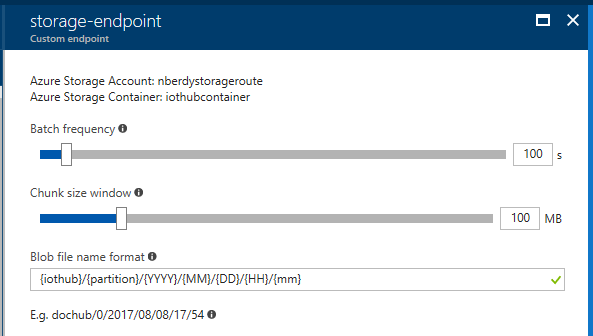
Incorrect Answers:
A: Azure Stream Analytics data source outputs: A streaming job can have multiple outputs. Supported outputs are Azure Event Hubs, Azure Blob storage, Azure
Table storage, Azure SQL DB, and Power BI.
References:
https://azure.microsoft.com/en-us/blog/route-iot-device-messages-to-azure-storage-with-azure-iot-hub/
Question 13
DRAG DROP -
You use Microsoft Azure Stream Analytics to analyze data from an Azure event hub in real time and send the output to a table named Table1 in an Azure SQL database. Table1 has three columns named Date, EventID, and User.
You need to prevent duplicate data from being stored in the database.
How should you complete the command? To answer, drag the appropriate values to the correct targets. Each value may be used once more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
Answer : 
Explanation:
Constraints are rules that the SQL Server Database Engine enforces for you. For example, you can use UNIQUE constraints to make sure that no duplicate values are entered in specific columns that do not participate in a primary key. Although both a UNIQUE constraint and a PRIMARY KEY constraint enforce uniqueness, use a UNIQUE constraint instead of a PRIMARY KEY constraint when you want to enforce the uniqueness of a column, or combination of columns, that is not the primary key.
Example:
ALTER TABLE Person.Password -
ADD CONSTRAINT AK_Password UNIQUE (PasswordHash, PasswordSalt);
GO -
References:
https://docs.microsoft.com/en-us/sql/relational-databases/tables/unique-constraints-and-check-constraints
Question 14
You have a Microsoft Azure SQL data warehouse that contains information about community events.
An Azure Data Factory job writes an updated CSV file in Azure Blob storage to Community/{date}/event.csv daily.
You plan to consume a Twitter feed by using Azure Stream Analytics and to correlate the feed to the community events.
You plan to use Stream Analytics to retrieve the latest community events data and to correlate the data to the Twitter feed data.
You need to ensure that when updates to the community events data is written to the CSV files, the Stream Analytics job can access the latest community events data.
What should you configure?
- A. an output that uses a blob storage sink and has a path pattern of Community /{date}
- B. an input that uses a data stream source and has a path pattern of Community/{date}/event.csv
- C. an input that uses a reference data source and has a path pattern of Community/{date}/event.csv
- D. an output that uses an event hub sink and the CSV event serialization format
Answer : C
Question 15
You are developing an application that uses Microsoft Azure Stream Analytics.
You have data structures that are defined dynamically.
You want to enable consistency between the logical methods used by stream processing and batch processing.
You need to ensure that the data can be integrated by using consistent data points.
What should you use to process the data?
- A. Apache Spark queries that use updateStateByKey operators
- B. a vectorized Microsoft SQL Server Database Engine
- C. a directed acyclic graph (DAG)
- D. Apache Spark queries that use mapWithState operators
Answer : D