Perform Data Engineering on Microsoft Azure HDInsight v7.0
Question 1
Note: This question is part of a series of questions that present the same Scenario.
Each question I the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution while others might not have correct solution.
You are implementing a batch processing solution by using Azure HDlnsight.
You have a table that contains sales data.
You plan to implement a query that will return the number of orders by zip code.
You need to minimize the execution time of the queries and to maximize the compression level of the resulting data.
What should you do?
- A. Use a shuffle join in an Apache Hive query that stores the data in a JSON format.
- B. Use a broadcast join in an Apache Hive query that stores the data in an ORC format.
- C. Increase the number of spark.executor.cores in an Apache Spark job that stores the data in a text format.
- D. Increase the number of spark.executor.instances in an Apache Spark job that stores the data in a text format.
- E. Decrease the level of parallelism in an Apache Spark job that Mores the data in a text format.
- F. Use an action in an Apache Oozie workflow that stores the data in a text format. Azure Data Factory linked service that stores the data in Azure Data lake. Azure DocumentDB database.
Answer : B
Question 2
Note: This question is part of a series of questions that present the same Scenario.
Each question I the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution while others might not have correct solution.
Start of Repeated Scenario:
You are planning a big data infrastructure by using an Apache Spark Cluster in Azure
HDInsight. The cluster has 24 processor cores and 512 GB of memory.
The Architecture of the infrastructure is shown in the exhibit:
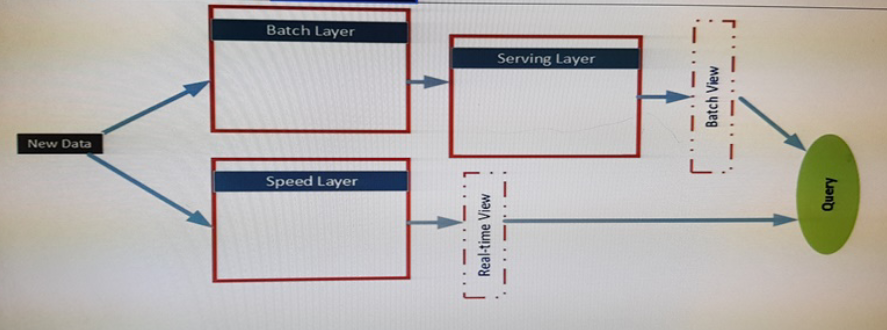
The architecture will be used by the following users:
* Support analysts who run applications that will use REST to submit Spark jobs.
* Business analysts who use JDBC and ODBC client applications from a real-time view.
The business analysts run monitoring quires to access aggregate result for 15 minutes.
The result will be referenced by subsequent quires.
* Data analysts who publish notebooks drawn from batch layer, serving layer and speed layer queries. All of the notebooks must support native interpreters for data sources that are bath processed. The serving layer queries are written in Apache Hive and must support multiple sessions. Unique GUIDs are used across the data sources, which allow the data analysts to use Spark SQL.
The data sources in the batch layer share a common storage container. The Following data sources are used:
* Hive for sales data
* Apache HBase for operations data
* HBase for logistics data by suing a single region server.
End of Repeated scenario.
You need to ensure that the support analysts can develop embedded analytics applications by using the least amount of development effort.
Which technology should you implement?
- A. Zeppelin
- B. Jupyter
- C. Apache Ambari
- D. Livy
Answer : B
Question 3
Note: This question is part of a series of questions that present the same Scenario.
Each question I the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution while others might not have correct solution.
HDInsight cluster that will provide in memory processing, interactive queries, and micro batch stream processing. The cluster has the following requirements:
Uses Azure Data Lake Store as the primary storage
Can be used by HDInsight applications.
What should you do?
- A. Use an Azure PowerShell Script to create and configure a premium HDInsight cluster. Specify Apache Hadoop as the cluster type and use Linux as the operating System.
- B. Use the Azure portal to create a standard HDInsight cluster. Specify Apache Spark as the cluster type and use Linux as the operating system.
- C. Use an Azure PowerShell script to create a standard HDInsight cluster. Specify Apache HBase as the cluster type and use Windows as the operating system.
- D. Use an Azure PowerShell script to create a standard HDInsight cluster. Specify Apache Storm as the cluster type and use Windows as the operating system.
- E. Use an Azure PowerShell script to create a premium HDInsight cluster. Specify Apache HBase as the cluster type and use Windows as the operating system.
- F. Use an Azure portal to create a standard HDInsight cluster. Specify Apache Interactive Hive as the cluster type and use Windows as the operating system.
- G. Use an Azure portal to create a standard HDInsight cluster. Specify Apache HBase as the cluster type and use Windows as the operating system
Answer : B
Question 4
You have an Apache Spark cluster in Azure HDInsight.
You plan to join a large table and a lookup table.
You need to minimize data transfers during the join operation.
What should you do?
- A. Use the reduceByKey function
- B. Use a Broadcast variable.
- C. Repartition the data.
- D. Use the DISK_ONLY storage level.
Answer : B
Question 5
You have an Azure HDlnsight cluster.
You need to build a solution to ingest real-time streaming data into nonrelational distributed database.
What should you use to build the solution?
- A. Apatite Hive and Apache Kafka
- B. Spark and Phoenix
- C. Apache Storm and Apache HBase
- D. Apache Pig and Apache HCatalog
Answer : C
Question 6
You have a text file named Data/examples/product.txt that contains product information.
You need to create a new Apache Hive table, import the product information to the table, and then read the top 100 rows of the table.
Which four code segments should you use in sequence? To answer, move the appropriate code segments from the list of code segments to the answer area and arrange them in the correct order.
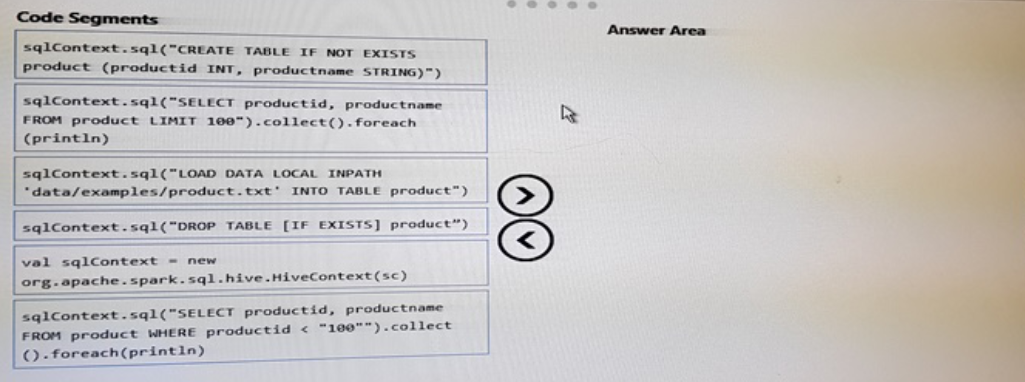
Answer : 
Question 7
Note: This question is part of a series of questions that present the same Scenario.
Each question I the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution while others might not have correct solution.
You need to deploy a NoSQL database to an HDInsight cluster. You will manage the servers that host the database by using Remote Desktop. The database must use the key/value pair format in a columnar model.
What should you do?
- A. Use an Azure PowerShell Script to create and configure a premium HDInsight cluster. Specify Apache Hadoop as the cluster type and use Linux as the operating System.
- B. Use the Azure portal to create a standard HDInsight cluster. Specify Apache Spark as the cluster type and use Linux as the operating system.
- C. Use an Azure PowerShell script to create a standard HDInsight cluster. Specify Apache HBase as the cluster type and use Windows as the operating system.
- D. Use an Azure PowerShell script to create a standard HDInsight cluster. Specify Apache Storm as the cluster type and use Windows as the operating system.
- E. Use an Azure PowerShell script to create a premium HDInsight cluster. Specify Apache HBase as the cluster type and use Windows as the operating system.
- F. Use an Azure portal to create a standard HDInsight cluster. Specify Apache Interactive Hive as the cluster type and use Windows as the operating system.
- G. Use an Azure portal to create a standard HDInsight cluster. Specify Apache HBase as the cluster type and use Windows as the operating system.
Answer : E
Question 8
You have an Azure HDInsight cluster.
You need to store data in a file format that maximizes compression and increases read performance.
Which type of file format should you use?
- A. ORC
- B. Apache Parquet
- C. Apache Avro
- D. Apache Sequence
Answer : A
Explanation: https://docs.microsoft.com/en-us/azure/data-factory/data-factory-supported- file-and-compression-formats
Question 9
Note: This question is part of a series of questions that present the same Scenario.
Each question I the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution while others might not have correct solution. enterprise data warehouse that will support in-memory analytics. The data warehouse must support connections that use the Microsoft Hive
ODBC Driver and Beeline. The data warehouse will be managed by using Apache
Ambari only.
What should you do?
- A. Use an Azure PowerShell Script to create and configure a premium HDInsight cluster. Specify Apache Hadoop as the cluster type and use Linux as the operating System.
- B. Use the Azure portal to create a standard HDInsight cluster. Specify Apache Spark as the cluster type and use Linux as the operating system.
- C. Use an Azure PowerShell script to create a standard HDInsight cluster. Specify Apache HBase as the cluster type and use Windows as the operating system.
- D. Use an Azure PowerShell script to create a standard HDInsight cluster. Specify Apache Storm as the cluster type and use Windows as the operating system.
- E. Use an Azure PowerShell script to create a premium HDInsight cluster. Specify Apache HBase as the cluster type and use Windows as the operating system.
- F. Use an Azure portal to create a standard HDInsight cluster. Specify Apache Interactive Hive as the cluster type and use Windows as the operating system.
- G. Use an Azure portal to create a standard HDInsight cluster. Specify Apache HBase as the cluster type and use Windows as the operating system
Answer : A
Question 10
Note: This question is part of a series of questions that present the same Scenario.
Each question I the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution while others might not have correct solution.
You are building a security tracking solution in Apache Kafka to parse Security logs. The
Security logs record an entry each time a user attempts to access an application. Each log entry contains the IP address used to make the attempt and the country from which the attempt originated.
You need to receive notifications when an IP address from outside of the United States is used to access the application.
Solution: Create a consumer and a broker. Create a file import process to send messages. Run the producer.
Does this meet the goal?
- A. Yes
- B. No
Answer : A
Question 11
You use YARN to manage the resources for a Spark Thrift Server running on a Linux based Apache Spark cluster in Azure HDInsight. You discover that the cluster does not fully utilize the resources. You want to increase resource allocation. You need to increase the number of executors and the allocation of memory to the Spark Thrift Server driver.
Which two parameters should you modify? Each correct answer presents part of the solution NOTE: Each correct selection is worth one point.
- A. spark.dynamicAllocation.maxExecutors
- B. spark.cores.max
- C. spark.executor.memory
- D. spark_thrift_cmd_opts
- E. spark.executor.instances
Answer : C,E
Explanation: https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-apache-spark- resource-manager
Question 12
You install the Microsoft Hive ODBC Driver on a computer that runs Windows 10 and has the 64-bit version of Microsoft Office 2016 installed.
You deploy a new Apache Interactive Hive cluster in Azure HDInsight. The cluster is hosted at myHDICluster.azurehdinsignt.net and contains a Hive table named hivesampletable that has 200,000 rows.
You plan to use HiveQL exclusively for the queries. The queries will return from 6,000 to
10,000 rows 90 percent of the time.
You need to configure a data source to ensure that you can use Microsoft Excel to access the data. The solution must ensure that the Hive queries execute as quickly as possible.
How should you configure the Advanced Options from the Microsoft Hive ODBC Driver
DSN Setup dialog box? To answer select the appropriate options in the answer area.
NOTE:
Each correct selection is worth one point.
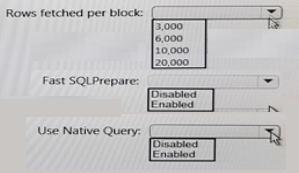
Answer : 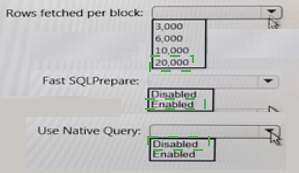
Question 13
Note: This question is part of a series of questions that present the same Scenario.
Each question I the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution while others might not have correct solution.
You are building a security tracking solution in Apache Kafka to parse Security logs. The
Security logs record an entry each time a user attempts to access an application. Each log entry contains the IP address used to make the attempt and the country from which the attempt originated.
You need to receive notifications when an IP address from outside of the United States is used to access the application.
Solution: Create two new brokers. Create a file import process to send messages.
Run the producer.
Does this meet the goal?
- A. Yes
- B. No
Answer : A
Question 14
You have an Apache HBase cluster in Azure HDInsight. The cluster has a table named sales that contains a column family named customerfamily.
You need to add a new column family named customeraddr to the sales table.
How should you complete the command? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once or not at all.
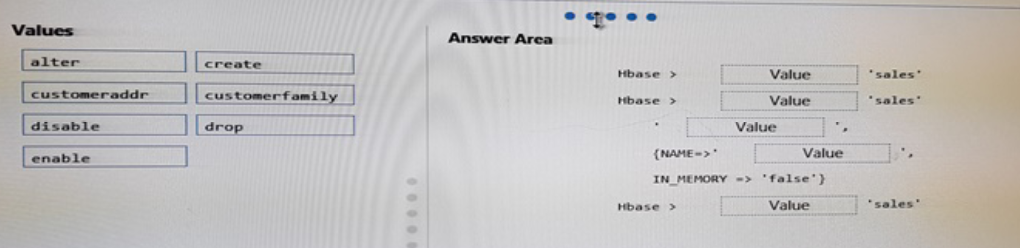
Answer : 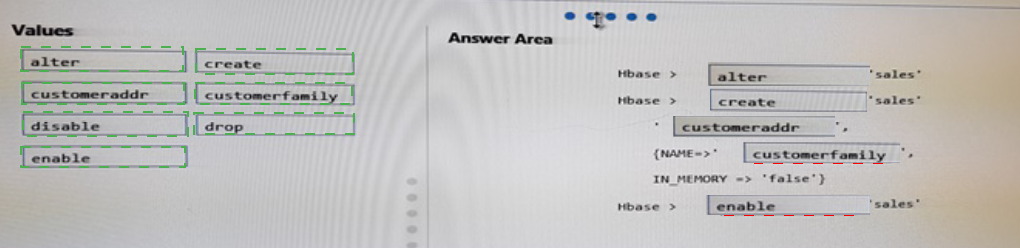
Question 15
Note: This question is part of a series of questions that present the same Scenario.
Each question I the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution while others might not have correct solution.
You are implementing a batch processing solution by using Azure HDlnsight.
You need to integrate Apache Sqoop data and to chain complex jobs. The data and jobs will implement MapReduce. What should you do?
- A. Use a shuffle join in an Apache Hive query that stores the data in a JSON format.
- B. Use a broadcast join in an Apache Hive query that stores the data in an ORC format.
- C. Increase the number of spark.executor.cores in an Apache Spark job that stores the data in a text format.
- D. Increase the number of spark.executor.instances in an Apache Spark job that stores the data in a text format.
- E. Decrease the level of parallelism in an Apache Spark job that Mores the data in a text format.
- F. Use an action in an Apache Oozie workflow that stores the data in a text format. Azure Data Factory linked service that stores the data in Azure Data lake. Azure DocumentDB database.
Answer : F