Perform Cloud Data Science with Azure Machine Learning v7.0
Question 1
Note: This question is part of a series of questions that present the same Scenario.
Each question I the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution while others might not have correct solution.
You have a dataset that contains a column named Column1. Column1 is empty.
You need to omit Column1 from the dataset. The solution must use a native module. Which module should you use?
- A. Clip Values
- B. Edit Metadata
- C. Import Data
- D. Normalize Data
- E. Execute Python Script
- F. Select columns in dataset
- G. Tune Model Hyperparamters
- H. Clean Missing data
Answer : F
Question 2
You have an Azure Machine Learning Environment.
You are evaluating whether to use R code or Python.
Which three actions can you perform by using both R code and Python in the Machine
Learning environment? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
- A. Preprocess cleanse, and group data.
- B. Score a training model.
- C. Create visualizations.
- D. Create an untrained model that can be used with the Train Model module.
- E. Implement feature ranking.
Answer : B,C,D
Question 3
Note: This question is part of a series of questions that present the same Scenario.
Each question I the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution while others might not have correct solution.
You need to use only one percent of an Apache hive Data table by conducting random sampling by groups.
Which module should you use?
- A. Normalize Data
- B. Tune Model Hyperparameters.
- C. Edit Metadata
- D. Clip Values
- E. Clean Missing Data
- F. Import Data
- G. Select Columns in Dataset
- H. Execute Python Script
Answer : H
Question 4
Note: This question is part of a series of questions that present the same Scenario.
Each question I the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution while others might not have correct solution.
You are designing an Azure Machine Learning workflow.
You have a dataset that contains two million large digital photographs.
You plan to detect the presence of trees in the photographs.
You need to ensure that your model supports the following:
* Hidden Layers that support a directed graph structure.
* User-defined core components on the GPU
Solution: You create a Machine Learning Experiment that implements the Multiclass Neural
Network Module.
Does this meet the goal?
- A. YES
- B. NO
Answer : A
Question 5
Note: This question is part of a series of questions that present the same Scenario.
Each question I the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution while others might not have correct solution.
Start of repeated Scenario:
A Travel agency named Margies Travel sells airline tickets to customers in the United
States.
Margies Travel wants you to provide insights and predictions on flight delays. The agency is considering implementing a system that will communicate to its customers as the flight departure near about possible delays due to weather conditions.
The flight data contains the following attributes:
* DepartureDate: The departure date aggregated at a per hour granularity.
* Carrier: The code assigned by the IATA and commonly used to identify a carrier.
* OriginAirportID: An identification number assigned by the USDOT to identify a unique airport (the flights Origin)
* DestAirportID: The departure delay in minutes.
*DepDet30: A Boolean value indicating whether the departure was delayed by 30 minutes or more ( a value of 1 indicates that the departure was delayed by 30 minutes or more)
The weather data contains the following Attributes: AirportID, ReadingDate (YYYY/MM/DD
HH), SKYConditionVisibility, WeatherType, Windspeed, StationPressure, PressureChange and HourlyPrecip.
End of repeated Scenario:
You need to use historical data about on-time flight performance and the weather data to predict whether the departure of a scheduled flight will be delayed by more than 30 minutes.
Which method should you use?
- A. Clustering
- B. Linear regression
- C. Classification
- D. anomaly detection
Answer : C
Explanation:
https://gallery.cortanaintelligence.com/Experiment/837e2095ce784f1ba5ac623a60232027
Question 6
Note: This question is part of a series of questions that present the same Scenario.
Each question I the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution while others might not have correct solution.
You are working on an Azure Machine Learning Experiment.
You have the dataset configured as shown in the following table:

You need to ensure that you can compare the performance of the models and add annotations to the results.
Solution: You save the output of the Score Model modules as a combined set, and then use the Project Columns modules to select the MAE.
Does this meet the goal?
- A. YES
- B. NO
Answer : A
Question 7
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario -
You plan to create a predictive analytics solution for credit risk assessment and fraud prediction in Azure Machine Learning. The Machine Learning workspace for the solution will be shared with other users in your organization. You will add assets to projects and conduct experiments in the workspace.
The experiments will be used for training models that will be published to provide scoring from web services.
The experiment tor fraud prediction will use Machine Learning modules and APIs to train the models and will predict probabilities in an Apache Hadoop ecosystem.
End of repeated scenario.
You plan to configure the resources for part of a workflow that will be used to preprocess data from files stored in Azure Blob storage. You plan to use Python to preprocess and store the data in Hadoop.
You need to get the data into Hadoop as quickly as possible.
Which three actions should you perform? Each correct answer presents pan of the solution.
NOTE: Each correct selection is worth one point.
- A. Create an Azure virtual machine (VM), and then configure MapReduce on the VM.
- B. Create an Azure HDInsight Hadoop cluster.
- C. Create an Azure virtual machine (VM), and then install an IPython Notebook server.
- D. Process the files by using Python to store the data to a Hadoop instance.
- E. Create the Machine Learning experiment, and then add an Execute Python Script module.
Answer : ACE
Question 8
You are analyzing taxi trips in New York City. You leverage the Azure Data Factory to create data pipelines and to orchestrate data movement.
You plan to develop a predictive model for 170 million rows (37 GB) of raw data in Apache
Hive by using Microsoft R Serve to identify which factors contributes to the passenger tipping behavior.
All of the platforms that are used for the analysis are the same. Each worker node has eight processor cores and 28 GB Of memory.
Which type of Azure HDInsight cluster should you use to produce results as quickly as possible?
- A. Hadoop
- B. HBase
- C. Interactive Hive
- D. Spark
Answer : A
Question 9
Note: This question is part of a series of questions that present the same Scenario.
Each question I the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution while others might not have correct solution.
Start of repeated Scenario:
A Travel agency named Margies Travel sells airline tickets to customers in the United
States.
Margies Travel wants you to provide insights and predictions on flight delays. The agency is considering implementing a system that will communicate to its customers as the flight departure near about possible delays due to weather conditions.
The flight data contains the following attributes:
* DepartureDate: The departure date aggregated at a per hour granularity.
* Carrier: The code assigned by the IATA and commonly used to identify a carrier.
* OriginAirportID: An identification number assigned by the USDOT to identify a unique airport (the flights Origin)
* DestAirportID: The departure delay in minutes.
*DepDet30: A Boolean value indicating whether the departure was delayed by 30 minutes or more ( a value of 1 indicates that the departure was delayed by 30 minutes or more)
The weather data contains the following Attributes: AirportID, ReadingDate (YYYY/MM/DD
HH), SKYConditionVisibility, WeatherType, Windspeed, StationPressure, PressureChange and HourlyPrecip.
End of repeated Scenario:
You plan to predict flight delays that are 30 minutes or more.
You need to build a training model that accurately fits the data. The solution must minimize over fitting and minimize data leakage. Which attribute should you remove?
- A. OriginAirportID
- B. DepDel
- C. DepDel30
- D. Carrier
- E. DestAirportID
Answer : B
Question 10
You have a dataset that is missing values in a column named Column3. Column3 is correlated to two columns named Column4 and Column5.
You need to improve the accuracy of the dataset, while minimizing data loss.
What should you do?
- A. Replace the missing values in Column3 by using probabilistic Principal Component Analysis (PCA).
- B. Remove all of the rows that have the missing values in Column4 and Column5.
- C. Replace the missing values in Column3 with a mean value.
- D. Remove the rows that have the missing values in Column3.
Answer : A
Question 11
You are building an Azure Machine Learning Experiment.
You need to transform 47 numeric columns into a set of 10 linearly uncorrelated features.
Which module should you add to the experiment?
- A. Principal Component Analysis
- B. K-Means Clustering
- C. Normalize data
- D. Group Data into Bins
Answer : A
Question 12
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario -
You plan to create a predictive analytics solution for credit risk assessment and fraud prediction in Azure Machine Learning. The Machine Learning workspace for the solution will be shared with other users in your organization. You will add assets to projects and conduct experiments in the workspace.
The experiments will be used for training models that will be published to provide scoring from web services.
The experiment tor fraud prediction will use Machine Learning modules and APIs to train the models and will predict probabilities in an Apache Hadoop ecosystem.
End of repeated scenario.
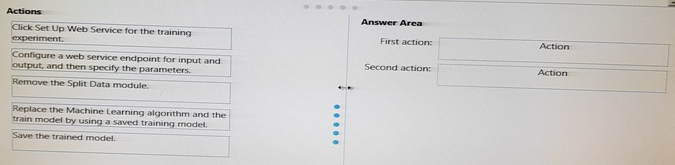
You finish training the model and are ready to publish a predictive web service that will provide the users with the ability to specify the data source and the save location of the results. The model includes a Split Data module.
Which two actions should you perform to convert the Machine Learning experiment to a predictive web service? To answer, drag the appropriate actions to the correct targets.
Each action may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Answer : 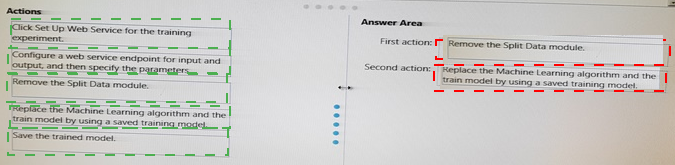
Question 13
You have data about the following:
* Users
* Movies
* User ratings of the movies
You need to predict whether a user will like a particular movie.
Which Matchbox recommender should you use?
- A. Item Recommendation
- B. Related items
- C. Rating Prediction
- D. Related Users.
Answer : B
Question 14
Note: This question is part of a series of questions that present the same Scenario.
Each question I the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution while others might not have correct solution.
You are designing an Azure Machine Learning workflow.
You have a dataset that contains two million large digital photographs.
You plan to detect the presence of trees in the photographs.
You need to ensure that your model supports the following:
* Hidden Layers that support a directed graph structure.
* User-defined core components on the GPU
Solution: You create a Machine Learning Experiment that implements the Multiclass
Decision Jungle Module.
Does this meet the goal?
- A. YES
- B. NO
Answer : B
Question 15
From the Cortana intelligence Gallery, you deploy a solution.
You need to modify the solution.
What should you use?
- A. Azure Stream Analytics
- B. Microsoft Power BI Desktop
- C. Azure Machine Learning Studio
- D. R Tools for Visual Studio
Answer : C
Explanation: https://docs.microsoft.com/en-us/azure/machine-learning/machine-learning- gallery-experiments