Implementing a SQL Data Warehouse v1.0
Question 1
DRAG DROP -
You have a Microsoft SQL Server Integration Services (SSIS) package that loads data into a data warehouse each night from a transactional system. The package also loads data from a set of Comma-Separated Values (CSV) files that are provided by your company"™s finance department.
The SSIS package processes each CSV file in a folder. The package reads the file name for the current file into a variable and uses that value to write a log entry to a database table.
You need to debug the package and determine the value of the variable before each file is processed.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:

Answer : 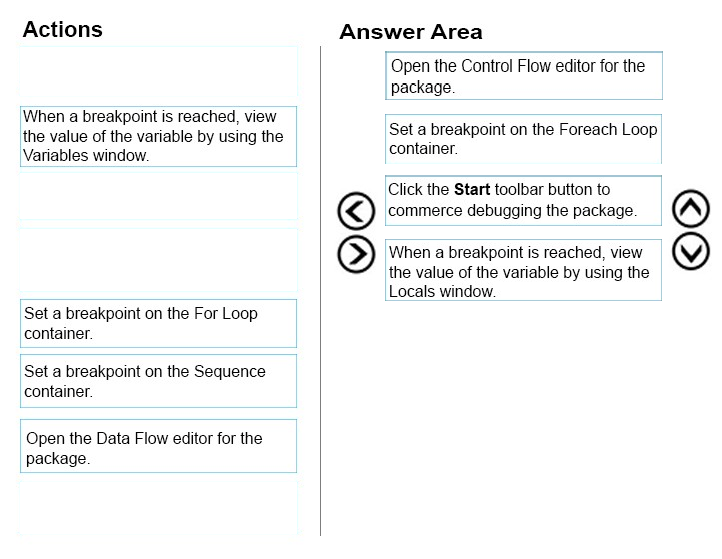
Explanation:
You debug control flows.
The Foreach Loop container is used for looping through a group of files. Put the breakpoint on it.
The Locals window displays information about the local expressions in the current scope of the Transact-SQL debugger.
References:
https://docs.microsoft.com/en-us/sql/integration-services/troubleshooting/debugging-control-flow http://blog.pragmaticworks.com/looping-through-a-result-set-with-the-foreach-loop
Question 2
HOTSPOT -
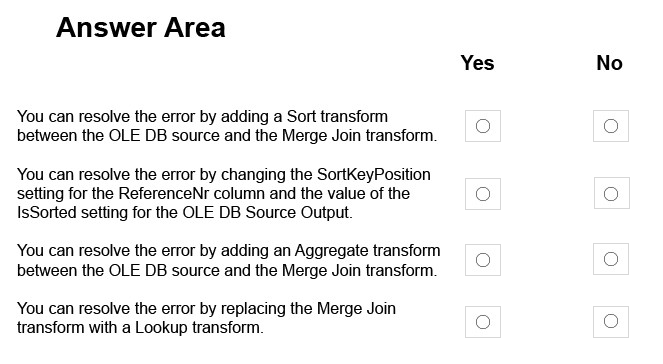
You create a Microsoft SQL Server Integration Services (SSIS) package as shown in the SSIS Package exhibit. (Click the Exhibit button.)
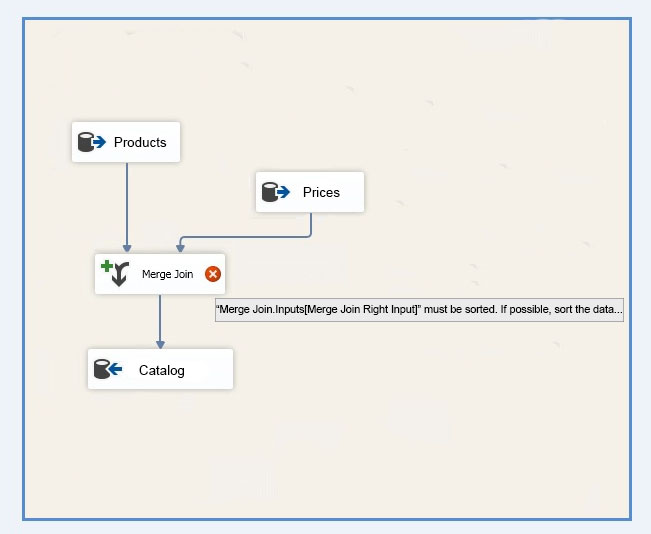
The package uses data from the Products table and the Prices table. Properties of the Prices source are shown in the OLE DB Source Editor exhibit (Click the
Exhibit Button.) and the Advanced Editor for Prices exhibit (Click the Exhibit button.)
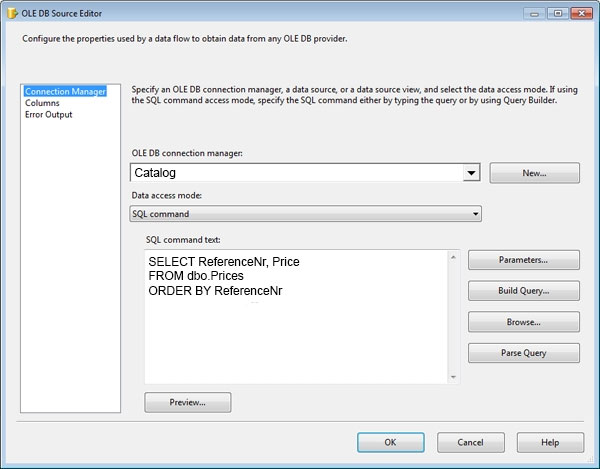
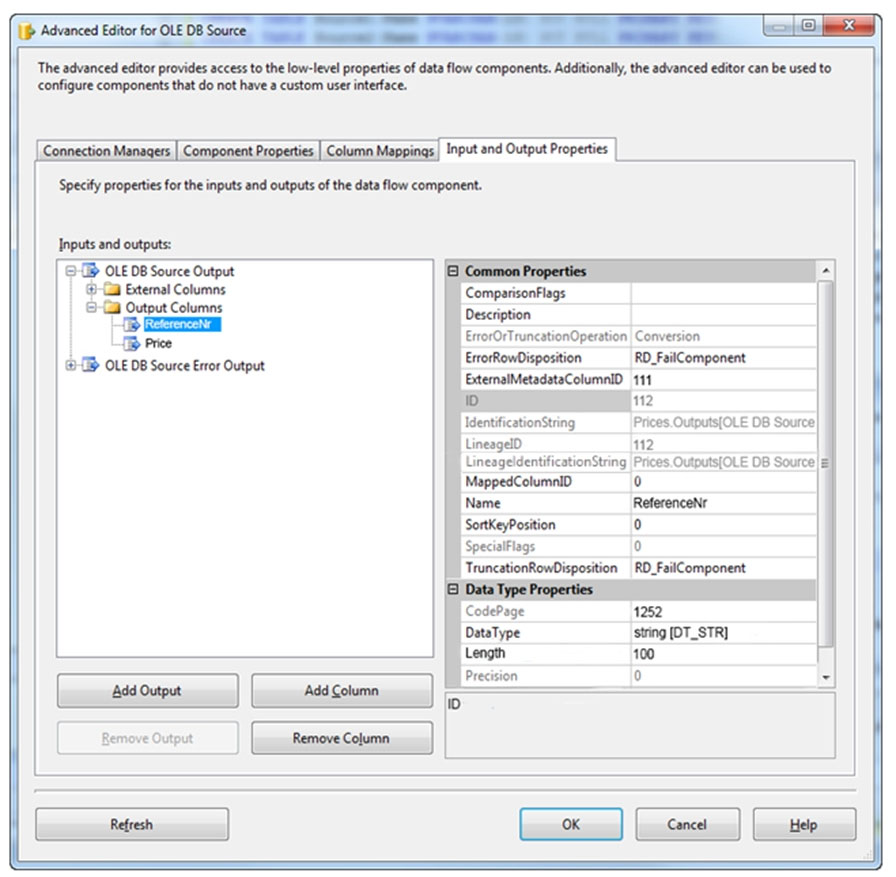
You join the Products and Prices tables by using the ReferenceNr column.
You need to resolve the error with the package.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer : 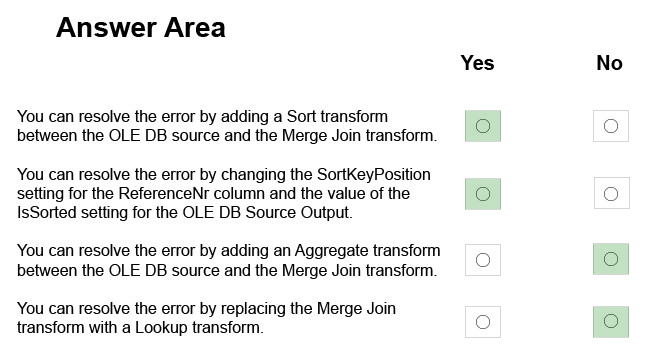
Explanation:
There are two important sort properties that must be set for the source or upstream transformation that supplies data to the Merge and Merge Join transformations:
The Merge Join Transformation requires sorted data for its inputs.
-> The IsSorted property of the output that indicates whether the data has been sorted. This property must be set to True.
-> The SortKeyPosition property of output columns that indicates whether a column is sorted, the column's sort order, and the sequence in which multiple columns are sorted. This property must be set for each column of sorted data.
If you do not use a Sort transformation to sort the data, you must set these sort properties manually on the source or the upstream transformation.
References:
https://docs.microsoft.com/en-us/sql/integration-services/data-flow/transformations/sort-data-for-the-merge-and-merge-join-transformations
Question 3
HOTSPOT -
You are testing a Microsoft SQL Server Integration Services (SSIS) package. The package includes the Control Flow task shown in the Control Flow exhibit (Click the Exhibit button) and the Data Flow task shown in the Data Flow exhibit. (Click the Exhibit button.)
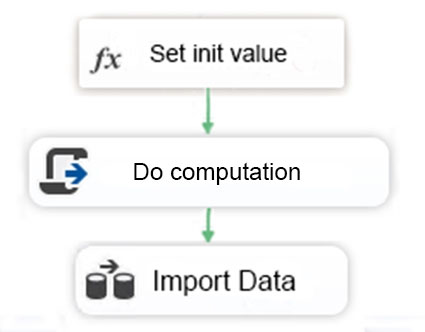
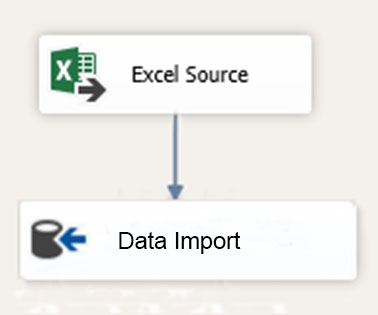
You declare a variable named Seed as shown in the Variables exhibit. (Click the Exhibit button.) The variable is changed by the Script task during execution.
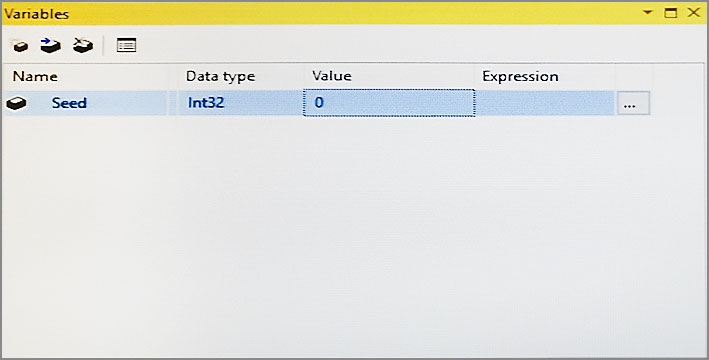
You need to be able to interrogate the value of the Seed variable after the Script task completes execution.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
Hot Area:

Answer : 
Explanation:
-> The Locals window displays variable that are local to the current statement, as well as three statements behind and in front of the current statement.
-> To use the Watch window you need to specify which variable you should watch.
-> MessageBox.Show can be used to display variables.
References:
https://docs.microsoft.com/en-us/sql/integration-services/variables-window
Question 4
HOTSPOT -
You have a database named DB1. You create a Microsoft SQL Server Integration Services (SSIS) package that incrementally imports data from a table named
Customers. The package uses an OLE DB data source for connections to DB1. The package defines the following variables.

To support incremental data loading, you create a table by running the following Transact-SQL segment:

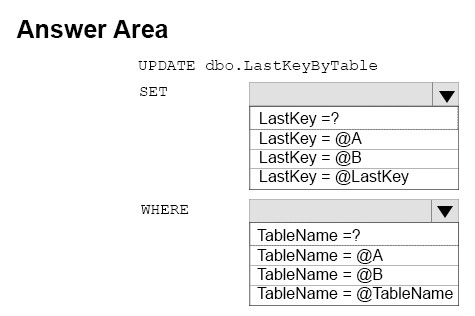
You need to create a DML statements that updates the LastKeyByTable table.
How should you complete the Transact-SQL statement? To answer, select the appropriate Transact-SQL segments in the dialog box in the answer area.
Hot Area:
Answer : 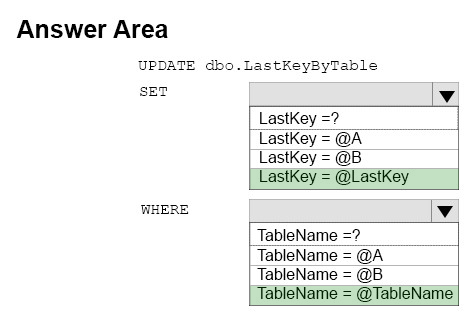
Question 5
DRAG DROP -
You deploy a Microsoft Server database that contains a staging table named EmailAddress_Import. Each night, a bulk process will import customer information from an external database, cleanse the data, and then insert it into the EmailAddress table. Both tables contain a column named EmailAddressValue that stores the email address.
You need to implement the logic to meet the following requirements:
-> Email addresses that are present in the EmailAddress_Import table but not in the EmailAddress table must be inserted into the EmailAddress table.
-> Email addresses that are not in the EmailAddress_Import but are present in the EmailAddress table must be deleted from the EmailAddress table.
How should you complete the Transact-SQL statement? To answer, drag the appropriate Transact-SQL segments to the correct locations. Each Transact-SQL segment may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
Select and Place:

Answer : 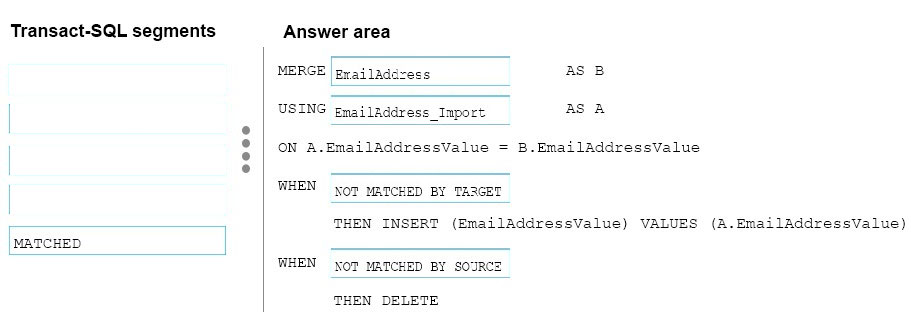
Explanation:
Box 1: EmailAddress -
The EmailAddress table is the target.
Box 2: EmailAddress_import -
The EmailAddress_import table is the source.
Box 3: NOT MATCHED BY TARGET -
Box 4: NOT MATCHED BY SOURCE -
References:
https://docs.microsoft.com/en-us/sql/t-sql/statements/merge-transact-sql
Question 6
DRAG DROP -
You administer a Microsoft SQL Server Master Data Services (MDS) model. All model entity members have passed validation.
The current model version should be committed to form a record of master data that can be audited and create a new version to allow the ongoing management of the master data.
You lock the current version. You need to manage the model versions.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area, and arrange them in the correct order.
Select and Place:

Answer : 
Explanation:
Box 1: Validate the current version.
In Master Data Services, validate a version to apply business rules to all members in the model version.
You can validate a version after it has been locked.
Box 2: Commit the current version.
In Master Data Services, commit a version of a model to prevent changes to the model's members and their attributes. Committed versions cannot be unlocked.
Prerequisites:
-> The version's status must be Locked.
-> All members must have validated successfully.
Box 3: Create a copy of the current version.
In Master Data Services, copy a version of the model to create a new version of it.
Note:
Reference:
https://docs.microsoft.com/en-us/sql/master-data-services/lock-a-version-master-data-services
Question 7
HOTSPOT -
You have a Microsoft SQL Server Integration Services (SSIS) package that contains a Data Flow task as shown in the Data Flow exhibit. (Click the Exhibit button.)
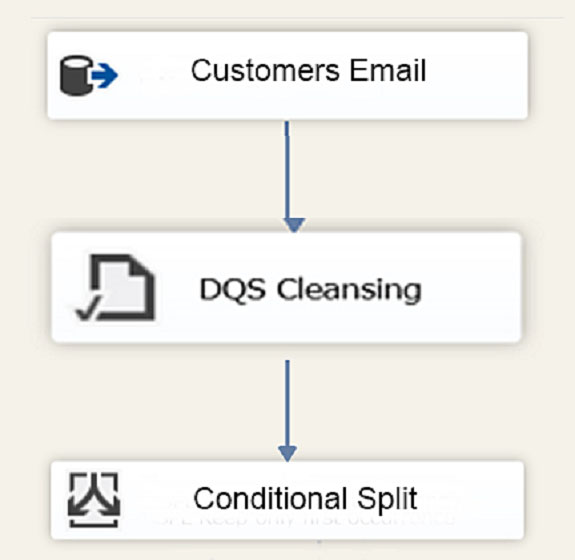
You install Data Quality Services (DQS) on the same server that hosts SSIS and deploy a knowledge base to manage customer email addresses. You add a DQS
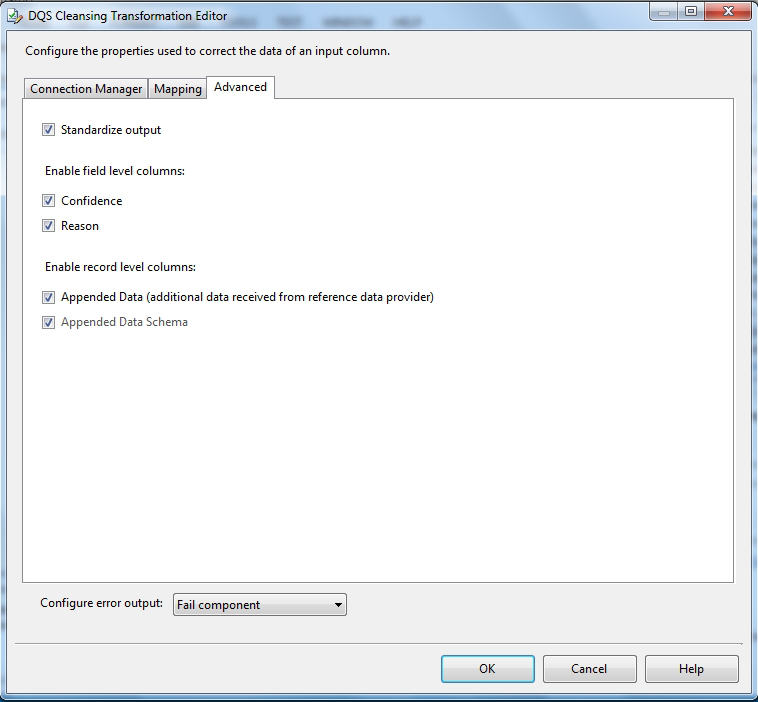
Cleansing transform to the Data Flow as shown in the Cleansing exhibit. (Click the Exhibit button.)
You create a Conditional Split transform as shown in the Splitter exhibit. (Click the Exhibit button.)
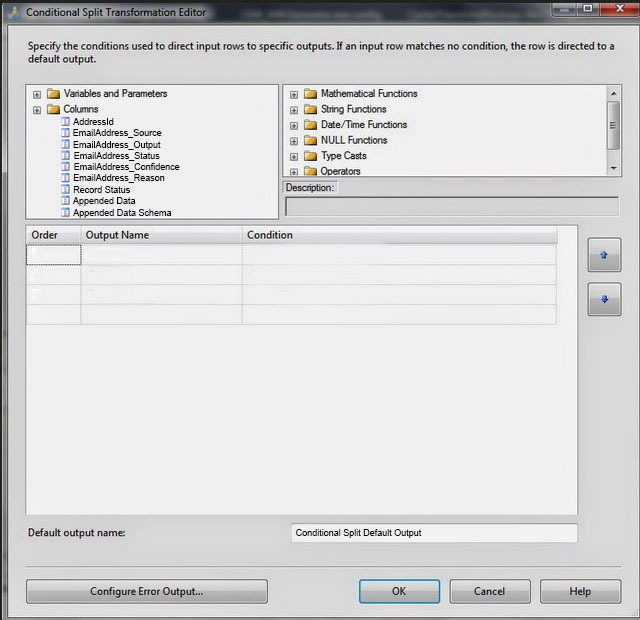
You need to split the output of the DQS Cleansing task to obtain only Correct values from the EmailAddress column.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
Hot Area:

Answer : 
Explanation:
The DQS Cleansing component takes input records, sends them to a DQS server, and gets them back corrected. The component can output not only the corrected data, but also additional columns that may be useful for you. For example - the status columns. There is one status column for each mapped field, and another one that aggregated the status for the whole record. This record status column can be very useful in some scenarios, especially when records are further processed in different ways depending on their status. Is such cases, it is recommended to use a Conditional Split component below the DQS Cleansing component, and configure it to split the records to groups based on the record status (or based on other columns such as specific field status).
References:
https://blogs.msdn.microsoft.com/dqs/2011/07/18/using-the-ssis-dqs-cleansing-component/
Question 8
You have a data quality project that focuses on the Products catalog for the company. The data includes a product reference number.
The product reference should use the following format: Two letters followed by an asterisk and then four or five numbers. An example of a valid number is
XX*55522. Any reference number that does not conform to the format must be rejected during the data cleansing.
You need to add a Data Quality Services (DQS) domain rule in the Products domain.
Which rule should you use?
- A. value matches pattern ZA*9876[5]
- B. value matches pattern AZ[*]1234[5]
- C. value matches regular expression AZ[*]1234[5]
- D. value matches pattern [a-zA-Z][a-zA-Z]*[0-9][0-9] [0-9][0-9] [0-9]?
Answer : A
Explanation:
For a pattern matching rule:
Any letter (A"¦Z) can be used as a pattern for any letter; case insensitive
Any digit (0"¦9) can be used as a pattern for any digit
Any special character, except a letter or a digit, can be used as a pattern for itself
Brackets, [], define optional matching
Example: ABC:0000 -
This rule implies that the data will contain three parts: any three letters followed by a colon (:), which is again followed by any four digits.
Question 9
HOTSPOT -
You have a series of analytic data models and reports that provide insights into the participation rates for sports at different schools. Users enter information about sports and participants into a client application. The application stores this transactional data in a Microsoft SQL Server database. A SQL Server Integration
Services (SSIS) package loads the data into the models.
When users enter data, they do not consistently apply the correct names for the sports. The following table shows examples of the data entry issues.

You need to create a new knowledge base to improve the quality of the sport name data.
How should you configure the knowledge base? To answer, select the appropriate options in the dialog box in the answer area.
Hot Area:
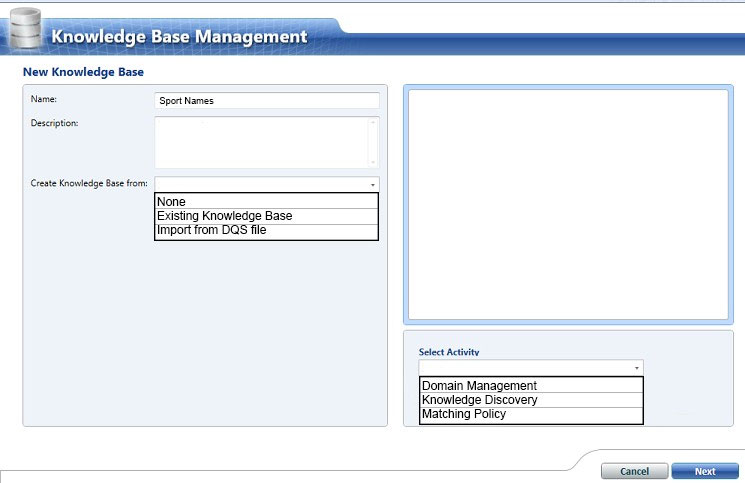
Answer : 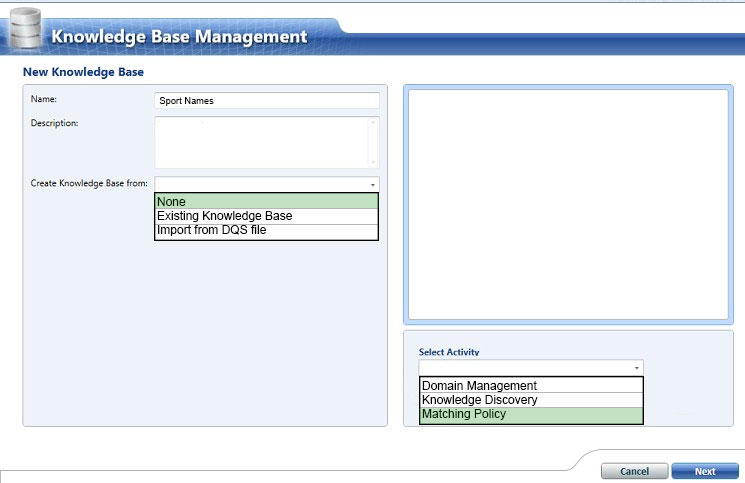
Explanation:
Spot 1: Create Knowledge base from: None
Select None if you do not want to base the new knowledge base on an existing knowledge base or data file.
Question 10
DRAG DROP -
You have a series of analytic data models and reports that provide insights into the participation rates for sports at different schools. Users enter information about sports and participants into a client application. The application stores this transactional data in a Microsoft SQL Server database. A SQL Server Integration
Services (SSIS) package loads the data into the models.
When users enter data, they do not consistently apply the correct names for the sports. The following table shows examples of the data entry issues.

You need to improve the quality of the data.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:

Answer : 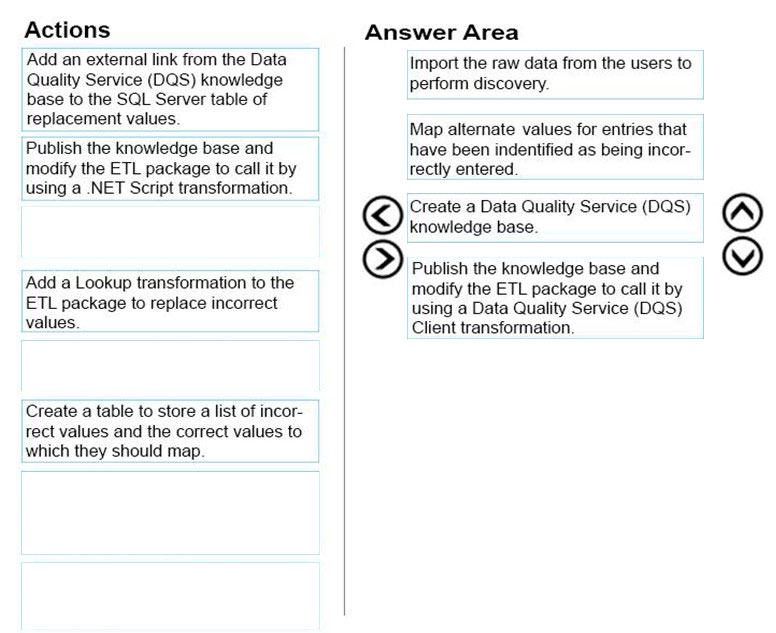
Explanation:
References:
https://docs.microsoft.com/en-us/sql/data-quality-services/perform-knowledge-discovery
Question 11
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a data warehouse that stores information about products, sales, and orders for a manufacturing company. The instance contains a database that has two tables named SalesOrderHeader and SalesOrderDetail. SalesOrderHeader has 500,000 rows and SalesOrderDetail has 3,000,000 rows.
Users report performance degradation when they run the following stored procedure:
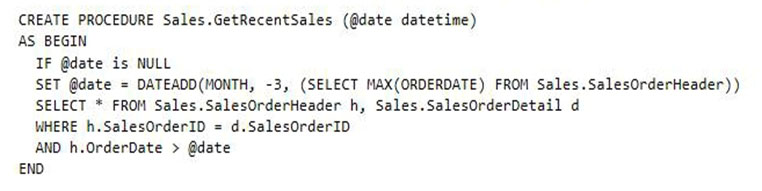
You need to optimize performance.
Solution: You run the following Transact-SQL statement:
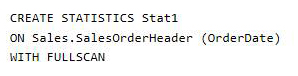
Does the solution meet the goal?
- A. Yes
- B. No
Answer : A
Explanation:
UPDATE STATISTICS updates query optimization statistics on a table or indexed view. FULLSCAN computes statistics by scanning all rows in the table or indexed view. FULLSCAN and SAMPLE 100 PERCENT have the same results.
References:
https://docs.microsoft.com/en-us/sql/t-sql/statements/update-statistics-transact-sql?view=sql-server-2017
Question 12
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to deploy a Microsoft SQL server that will host a data warehouse named DB1.
The server will contain four SATA drives configured as a RAID 10 array.
You need to minimize write contention on the transaction log when data is being loaded to the database.
Solution: You replace the SATA disks with SSD disks.
Does this meet the goal?
- A. Yes
- B. No
Answer : B
Explanation:
A data warehouse is too big to store on an SSD.
Instead you should place the log file on a separate drive.
References:
https://docs.microsoft.com/en-us/sql/relational-databases/policy-based-management/place-data-and-log-files-on-separate-drives?view=sql-server-2017
Question 13
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to deploy a Microsoft SQL server that will host a data warehouse named DB1.
The server will contain four SATA drives configured as a RAID 10 array.
You need to minimize write contention on the transaction log when data is being loaded to the database.
Solution: You add more data files to DB1.
Does this meet the goal?
- A. Yes
- B. No
Answer : B
Explanation:
There is no performance gain, in terms of log throughput, from multiple log files. SQL Server does not write log records in parallel to multiple log files.
Instead you should place the log file on a separate drive.
References:
https://www.red-gate.com/simple-talk/sql/database-administration/optimizing-transaction-log-throughput/ https://docs.microsoft.com/en-us/sql/relational-databases/policy-based-management/place-data-and-log-files-on-separate-drives?view=sql-server-2017
Question 14
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to deploy a Microsoft SQL server that will host a data warehouse named DB1.
The server will contain four SATA drives configured as a RAID 10 array.
You need to minimize write contention on the transaction log when data is being loaded to the database.
Solution: You configure the server to automatically delete the transaction logs nightly.
Does this meet the goal?
- A. Yes
- B. No
Answer : B
Explanation:
You should place the log file on a separate drive.
References:
https://www.red-gate.com/simple-talk/sql/database-administration/optimizing-transaction-log-throughput/ https://docs.microsoft.com/en-us/sql/relational-databases/policy-based-management/place-data-and-log-files-on-separate-drives?view=sql-server-2017
Question 15
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Microsoft Azure SQL Data Warehouse instance. You run the following Transact-SQL statement:

The query fails to return results.
You need to determine why the query fails.
Solution: You run the following Transact-SQL statements:
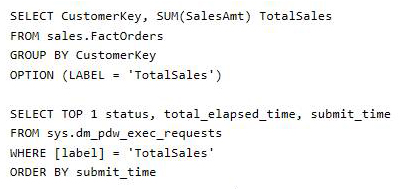
Does the solution meet the goal?
- A. Yes
- B. No
Answer : A
Explanation:
To use submit_time we must use sys.dm_pdw_exec_requests table, which holds information about all requests currently or recently active in SQL Data
Warehouse. It lists one row per request/query.
Label is an Optional label string associated with some SELECT query statements.
References:
https://docs.microsoft.com/en-us/sql/relational-databases/system-dynamic-management-views/sys-dm-pdw-exec-requests-transact-sql?view=aps- pdw-2016-au7